Scrapebox: a new perspective on an old SEO tool
Scrapebox is a versatile SEO tool but it’s mainly known for its comment spamming functions. The purpose of this article is to show that this software offers many interesting features that could be applied to academic and market reasearch. For the sake of brevity, we will focus our review on 3 core tools offered by Scrapebox: the Keyword Scraper, the URL Harvester and Meta-data/Comments Scraper.
Overview
Scrapebox was developed for SEO purposes, its popularity peaked a couple of years ago before search engines adjusted their algorithms in order to penalize comment spamming backlinks.
In addition to the features examined in this review, it offers several and variegated functions like proxy testing, spun comment spamming, page and domain PR scraping, etc. Being born as a “spamming” tool, its core strength is the ability to manage huge amounts of data. Most of its tools can manage up to one million inputs and theoretically an infinite amount of outputs per operation. Even though it doesn’t have many analytic capabilities, we suggest that its powerful data gathering features could be productively used outside the SEO sphere.
Keyword Scraper
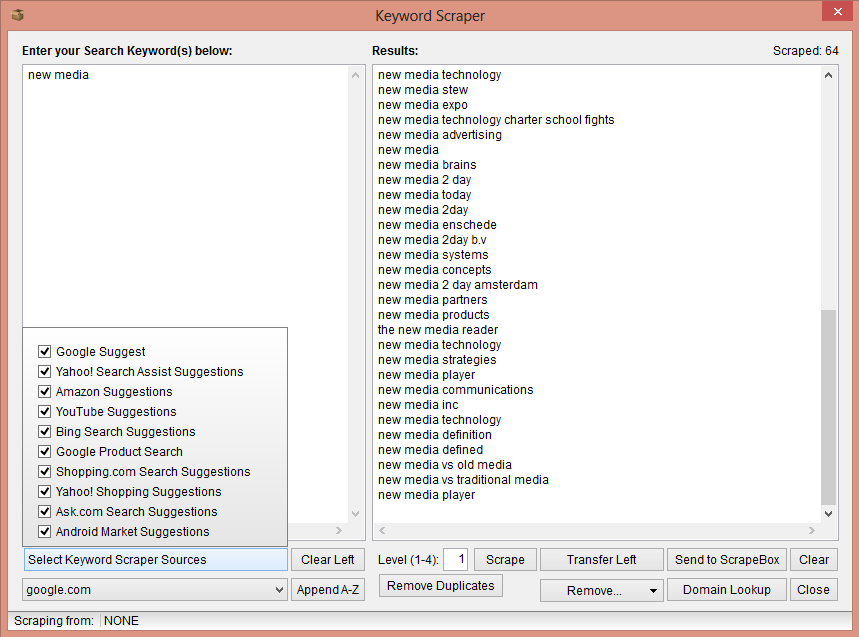
Keyword scraper – One of the many functions of Scrapebox. The bottom left box shows all the sources that this software uses to scrape related keywords.
Scrapebox can scrape related keywords from several popular internet services listed in the picture above. This function is based on the suggestions offered by these websites when the user starts typing the query. It is worth mentioning that it is possible to select the sources and then compare them. It is also possible to scrape these suggestions from different nations, since proxies are supported for every tool provided by this software. There are 4 depth levels available, this means that it is possible to scrape automatically the additional suggestions that are shown when the user types the first level suggestions.
These features give the opportunity to examine how the same concepts are linguistically approached by different internet services. Doing this type of analysis could give an insight on the technical differences of search algorithms. Testing the hypothesis that Amazon’s search algorithm conceptualizes words in a more commercial way than Google’s, could be an example. As mentioned before, this tool has the capability of scraping from different search engines and from different locations. Therefore it could be possible to make a study on the various linguistic correlations and differences that countries have on web.
URL Harvester
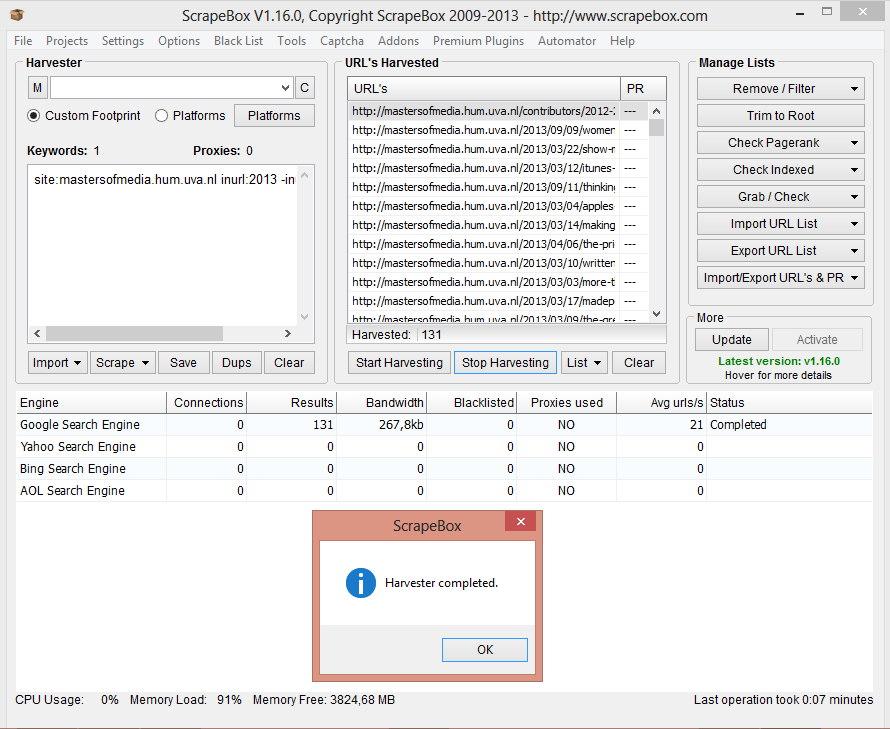
Search Engine Scraper – Scrapebox can scrape SERP URLs from Google, Yahoo, Bing and AOL.
Another interesting function that Scrapebox provides is the URL Harvester, a simple but flexible tool to scrape from the most popular search engines: Google, Bing, Yahoo and AOL. The user needs to input a set of keywords and the software gathers all the URLs from search engine results for that keywords. Search engines provide one thousand results per keyword but Scrapebox is able to restrict the selection to any number of results (e.g. only the top 10 results). Moreover, there is the option to scrape the same search engine in different languages/versions (google.com, google.nl, etc). As shown in the picture, it is possible to use advanced search operators like “site:” and “inurl:”.
One of the many ways to use this tool could be to track down censorship. Performing a search with the same keyword, but in different countries each time, would result in a list of the most popular sites. In case one or more URL are missing from a country’s list, while they appear on most of the others, then this might be a sign of censorship. Scrapebox also offers a tool for URL lists comparison that could be used for this purpose.
Meta-data/Comment Scraper

Meta Data Scraper – In this picture Scrapebox is scraping Titles, descriptions and keywords for the Masters of Media Blog.
This last tool is meant to extract HTML metadata (Title, Description and Keywords) and comments from long list of URLs. As shown in the picture, this feature appears to have a bug since it is missing some URLs. This is a potential problem to be addressed before considering this tool for research purposes, although this might have been caused by an internet connection problem. The last software update was on the 30th of August 2013, so there is a reasonable chance that if there are any problems they will be taken care of.
Those last two tools work in synergy and can be used for data retrieving tasks. Their capabilities though do not end here. They could, for example, be used in order to discover trends that emerge from heated social debates. To be more specific, these tools could be used to study how keywords such as terrorism, Islam or 9/11 are interpreted in different countries and if those interpretations form trends. The search engine results for a specific keyword could be extracted in form of a list by using the URL Harvester. The next step would be to import this list into the Meta-Data Scraper and examine the new keywords that emerge. Having this new data set at hand, a statistical analysis could be performed in order for patterns to appear (e.g. secondary keyword appearance frequency). Those patterns could indicate trends that are forming into the web and therefore in a fraction of the society too. Moreover, repeating the same procedure over time, a study could be made on how specific trends grow and decay.
Conclusion
In conclusion, this was far from a complete analysis of the tool. The purpose of this article, though, was to suggest some alternative applications of this interesting software.