Why Twitter can be the Next Big Thing in Scientific Collaboration
Introduction
Imagine yourself in the following situation: You, a scientist pur sang, are busy researching and analyzing A and you are having doubts about the values in the model, suspecting a technical error. Without hesitation, you compose a tweet describing the research and the problem, attach a photo made of the model, add a hashtag (e.g. #science or #labhelp) and send it to Twitter. A few moments later six people have replied with an answer and your problem is solved.
While this looks like a fairytale, computation in general has become more and more embedded and is starting to play a fundamental role in science in the last couple of years. Scientists have always been among the first to adopt and use new communication technologies into their field of work; technologies such as wiki’s, e-mail and instant messaging (Sonnenwald, 2007).
It can be said that computation in the field of science will become even bigger, due to the new upcoming generation of “social media-scientists”: scientists who grew up in the age of Facebook, Wikipedia and Twitter, and who are used to collaborate and communicate globally online. Not only do our “future scientists” already generate an enormous amount of data, also referred to as the data tsunami[1], but will only continue to increase this amount, since more forms of collaboration with social media are appearing.
While more data isn´t necessarily always better data, James Surowiecki argues that we are now living in the age of “the wisdom of the crowds”. Here, the larger the group of people collaborating and communicating is, the better the results will be. A classic scenario of one and one is three.
Wisdom of the scientific crowd
There are currently already a few tools that are providing in the creation of collective wisdom, making possible scientific collaborations through (social) media. A first group of examples can be seen in the rise of collaborative analysis tools such as IBM´s Many Eyes and Chartle. Here, people create graphs and charts of big amounts of data and are able to share and discuss them with others. By first choosing a dataset, a user can then choose a visualization, customize it and then publish it to the internet for everyone to see [2].
A second, better known example is Wikipedia: a collaborative digital encyclopedia launched in 2001 by Jimmy Wales. At the moment of writing the English version of the website contains a total of 3.622.868 articles and more than 450 million collaborative edited pages [3]. While the encyclopedia is open and accessible to everyone, the adding and editing of articles isn’t: to do this one needs to have a registered account on the website. Also, studies have been done on the reliability of the entries in Wikipedia, mostly ending up quite positive (Magnus, 2008 & Schiff, 2006). Furthermore, it has also been researched that a majority of college students use the website for course-related research, mostly by providing background information (Lee, 2010). Wikipedia is a general form of encyclopedia, containing articles on many different subjects. How these subjects can be categorized is displayed in figure 1.

Figure 1: Differences in Wikipedia's category structure and the Universal Decimal Classification
The classification in Wikipedia is however a bit different than that of the more taxonomy based Universal Decimal Classification (UDC). In Wikipedia the structure of classification seems to be more wide-spread and focused on Arts & Entertainment. Also, we can see that science (light and dark blue) is practically anywhere in the Wiki-sphere, where in UDC they are more clustered together.
Why Twitter and Why Not
In short: I do believe Twitter can play an important role in the field of science and in scientific collaboration. As argued by Mark Granovetter, who wrote about the effects of social and professional networks on information diffusion, innovation often travels most effectively via weak connections (Grannovetter, 1973). In order for scientific collaboration to happen, information must thus be able to diffuse among people or groups.
I hereby argue that Twitter enables this form of information diffusion. In Twitter, a user has “followers” who aren’t necessarily “friends”. Unlike other social media, followers don’t have to be approved by the one that is being followed (but of course can be blocked). This means that everyone can follow everyone, and can then read everything that is being ‘tweeted’ by the followed user without any real acceptance. In order to find users of interest, Twitter has implemented a powerful search mechanism that makes it easy to search for a specific topic and see all tweets on that topic. If someone likes what another user has said, he or she can choose to follow the user and read all future tweets. Retweeting a tweet then spreads the message across their own networks, creating a cascade effect of information and showing that the diffusion of information indeed travels via weak ties.
A scientist can thus reach a huge amount of people, when for example he/she is in need of help, by simply composing a tweet and sending it on Twitter.
There are currently already networks of scientists on Twitter, as for example can be seen in figure 2.
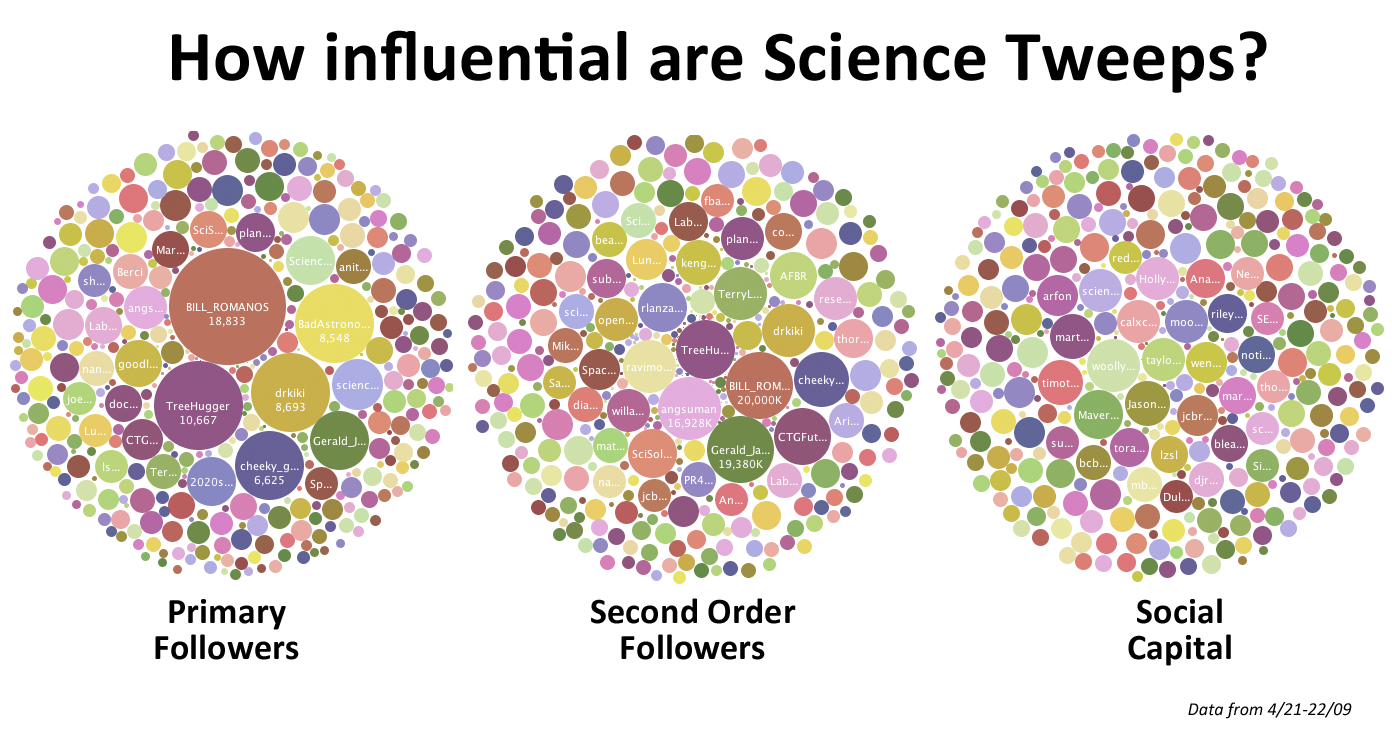
Figure 2
An interactive version of this can be seen on Many Eyes. The figure is generated from a list of Scientific Twitter Friends of David Bradley and is visualized by 2020 Science. The bubble-chart shows how influential a Scientific Twitter User in the list might be and that Twitter can indeed be used for the connection (and collaboration) between scientists.
While this does sound like a perfect tool for scientific collaboration, there are some downsides in using social media and Twitter according to a survey held under 300 lab managers[4]. They explain that the reasons for not adopting social media are:
- Blurring of the boundaries between private and business use
- Loss of productivity
- Security: the danger of confidential information being leaked
These all make a point of course, but these ‘downsides’ can all be avoided when carefully using these social media and by paying attention on what information is being spread.
Footnotes:
[1] http://thesocialcustomer.com/peterauditore1/37255/social-media-data-tsunami, accessed on 27 april 2011
[2] http://www-958.ibm.com/software/data/cognos/manyeyes/page/create_visualization.html, accessed on 28 april 2011
[3] http://en.wikipedia.org/wiki/Special:Statistics, accessed on 27 april 2011
[4] These results were published in Lab Manager Magazine and can be found online at http://www.labmanager.com/?articles.view/articleNo/4496/
References:
Granovetter, M. S. (1973), “The Strenght of Weak Ties”, American Journal of Sociology, Vol. 78, No. 6 (May 1973), 1360-1380.
Sonnenwald, D. H. (2007), “Scientific Collaboration: A Synthesis of Challenges and Strategies”, Annual Review of Information Science and Technology, Vol. 4, Blaise Cronin, (Ed,), Medford, NJ: Information Today.
Surowiecki, J. (2004), “The Wisdom of Crowds: Why the Many Are Smarter Than the Few and How Collective Wisdom Shapes Business, Economies, Societies and Nations”, Little Brown
Auditore, P. (2011), “The Social Media Data Tsunami”, The Social Customer, 27 April, accessed on 27 April 2011, http://thesocialcustomer.com/peterauditore1/37255/social-media-data-tsunami
Magnus, P.D. (2008), “Early response to false claims in Wikipedia,” First Monday, 13(9), September, accessed on 27 April 2011.
http://www.uic.edu/htbin/cgiwrap/bin/ojs/index.php/fm/article/viewArticle/2115/2027/
Schiff, S. (2006). “Know it all. Can Wikipedia conquer expertise?” The New Yorker. 31 July, accessed on 28 April 2011. http://www.newyorker.com/archive/2006/07/31/060731fa_fact/.
Lee, A. (2010), “Science students more likely to use Wikipedia”, The Daily Princetonian, 23 March, accessed on 28 april 2011. http://www.dailyprincetonian.com/2010/03/23/25575/