Big data, long data and… ephemeral data?
Currently the topic of data is mostly approached in terms of volume and temporal scope – a perspective translated in expressions such as “big data” and “long data”. Nevertheless, these terms are somehow abstract to most users and only start to become attainable when the focus moves to personal data. In this particular domain, the primarily voiced concern relates to privacy issues but this discussion is acquiring new contours going beyond the “private versus public” matter to also question the longevity of personal data.

Big data is a relatively recent term [1] but is surely one of the main buzzwords in technology and business articles and a trending topic in many debates surrounding innovation in present days.
At a superficial glance, the expression seems to emphasize the quantity of data which can now be potentially captured, processed and analyzed: in theoretical terms, big data would incorporate data on virtually everything about nearly everyone. However, the genuine novelty moves beyond the linearity of dimension to focus on the relationality aspect. As stated by Manovich in his 2011 article “Trending: The Promises and the Challenges of Big Social Data”, big data allows the combination of surface data (macro level data) with deep data (micro level data) which can then lead to the establishment of connections between datasets unveiling patterns which were previously not visible [2]. When correctly analyzed, such patterns would generate meaningful information and ultimately knowledge and wisdom [3]. It is the announcement of an era portrayed simultaneously as exciting and challenging.
Long data
What if volume and relationality were still insufficient data elements to produce truly insightful information? In a recent Wired article “Stop Hyping Big Data and Start Paying Attention to ‘Long Data’”, Samuel Arbesman stresses out the temporality of data as an essential contextualizing element. The author coins the term “long data” to refer to datasets that have “massive historical sweep” which would provide a much more comprehensive and accurate picture of humankind.
The argument is logical but one cannot help but question its realism and pragmatism – how big can the data of past events be? Surely it is possible to channel efforts to further systematize and analyze past (existing) data [4] but what happens when data is simply non-existent due to lack of past records? Perhaps this new expression should be mainly interpreted as a provocation [5] with the intent of widening the horizons of big data analysis and release it from the limited perspective of single snapshots taken in the present time.
Ephemeral data – the present and the future of personal information
The macro level trends are delineated and point to a certain direction, but how are these patterns reflected on a micro level? What are the implications of big data and long data in the life of each one of us as citizens from a social, economic and political point of view? Or as digital users from a psychological and emotional perspective? It is a complex matter to which there is probably no succinct answer.
As Professor of Cognitive Science and Communications at Cornell University Jeff Hancock states, humankind has evolved to communicate in a manner to which there is no record [6]. However, the network age in which we currently live overthrows that concept – today most individuals can, consciously and very easily, record most of their thoughts, words and actions throughout the span of a lifetime. Moreover, in many cases, this registration process is already taking place with or without the full consent (or complete awareness) of the individuals – social media networks being the most commonly cited example to illustrate such practice.
Information shared within a certain context for a specific purpose and a particular audience is converted into data records detached from their origin and subject to innumerous correlations with other datasets in a continuous manner. The boundaries between public and private information become increasingly blurred raising fundamental questions on privacy matters (and also leading to ethical discussions [7]).
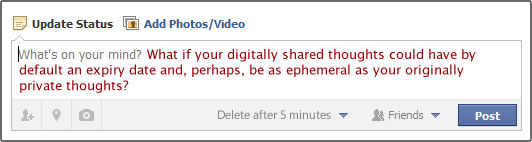
Is it possible that this personal data legacy is a burden too heavy for any individual to carry permanently and that this acknowledgment is giving rise to a backlash? In the last months several news articles [8] focused on this topic announcing an emerging trend which can be labeled as impermanent social media with popular mobile apps such as Snapchat, where users can send self-destructing photos to one or more recipients, or Wickr which follows the same logic by allowing the sender to select the expiry date of a diversity of media types including text, picture, audio and video under the motto “The Internet is forever. Your private communications don´t need to be.”
For those who might deem such applications as another passing fashion applicable to content of dubious nature, it is important to state that this desire for “data impermanence” is not merely translated into a business need but also emerges as a political concern. In January 2012 Viviane Reding, Vice-President of the European Commission, proposed privacy legislation which included a right-to-be-forgotten provision based on the premise that “if an individual no longer wants his personal data to be processed or stored by a data controller, and if there is no legitimate reason for keeping it, the data should be removed from their system.” [9] It is then no longer simply a matter of the private versus the public status of personal information but also the temporal validity of the same.
In a world where the digital birth of a human being can already precede the analog physical birth [10], how can this increasing public desire and demand for data ephemerality be successfully met? And to which extent is this tendency compatible with other trends which encourage personal tracking in several areas ranging from fitness [11] to finance [12] (culminating in the “quantified-self” movement [13]])? If ephemeral would become the new default status of personal data, could this seriously undermine the maintenance of a global data system? In such case, what would be the consequences for individuals and organizations?
———
[1] As a reference, the Wikipedia entry for “big data” was created in April 2010. [back to main text]
.
[2] On this matter, it is important to refer that the sheer volume of data available nowadays can end up producing misleading information in many occasions. As authors Danah Boyd and Kate Crawford point out in the 2011 paper “Six Provocations for Big Data”, big data may instigate “the practice of apophenia: seeing patterns where none actually exist.” [back to main text]
.
[3] This hierarchy is commonly represented by the DIKW (Data, Information, Knowledge and Wisdom) Pyramid. [back to main text]
.
[4] One illustrative example would be Google Lab’s Ngram Viewer project analyzing 5 million books published in a timeframe of 200 years. See Jean-Baptiste Michel and Erez Lieberman Aiden’s presentation about the project. [back to main text]
.
[5] In 2008, still in the topic of data, the editor in chief of Wired, Chris Anderson, announced the end of the scientific method in the era of big data in another controversial article entitled “The End of Theory: The Data Deluge Makes the Scientific Method Obsolete.” [back to main text]
.
[6] In order to understand the contextualization of the statement, watch the presentation on “The future of lying”. [back to main text]
.
[7] As an academic reference, see the 2010 paper published by Michael Zimmer “‘But the Data is already Public’: On the Ethics of Research in Facebook” exploring the privacy and ethical issues raised by a 2008 academic project which collected data from the Facebook accounts of an entire cohort of college students. [back to main text]
.
[8] As a reference, see “Snapchat and the Erasable Future of Social Media” and “What UIs Need Now: Built-In Options To Destroy Data”. [back to main text]
.
[9] Read the Press Release on this proposal in its entirety. [back to main text]
.
[10] As stated by photojournalist Rick Smolan in “How ‘big data’ is changing lives” as part of BBC News – What if? season. [back to main text]
.
[11] The most mediatized examples in this domain are probably Nike’s Fuelband and Jawbone’s UP. [back to main text]
.
[12] One of the most popular applications in this field is Mint. [back to main text]
.
[13] As a reference, visit the Quantified Self (self knowledge through numbers) website. [back to main text]..