Digital Hangovers: Capturing an Emergent New Media Phenomenon through DigitalObservatory

Introduction
Modern technology has led to a rapidly increasing amount of media objects that can be shared online. Every minute, for instance, more than hundred videos are uploaded on Youtube. Yet, the downside of this development is that what exists online can circulate on the web for a long time – even if you rather not have that one that one embarrassing video, image or text of yourself out there. Although this emerging phenomenon, which we have come to call the “digital hangover,” raises many issues around privacy, ownership, memory, access and the like, it has yet to be properly situated and conceptualized in academic studies.
Through our project DigitalObservatory, we aim to critically reflect on and engage with the “digital hangover” as an emerging new media phenomenon. Because our final project is a non-linear examination of a phenomenon, this blogpost is a linear documentation of the process our project went through and the goals it hopes to achieve, which is the subject of our first chapter. In addition, it is also an exploration of the theoretical questions and themes our project has led us to. Therefore, the second chapter examines three subgenres or conditions of the “digital hangover,” which are, in order of appearance: networkedness, storage and retrieval, and encoding and appropriation.
1. Project Process and Goal
From the start of our project, our goal was to understand the emerging phenomenon of the “digital hangover.” However, the end product of the DigitalObservatory is also the result of certain roads not taken. The original idea for approaching the trend of the “digital hangover” was to devise an online test that allowed web users who were suffering from the consequences of embarrassing content online first, to see which category their hangover fitted into, and second, to read advice on what they should do to recover from their hangover, for instance delete their social network profile. In addition, we would provide an academic reflection of this new media occurrence on the same website. Yet, although we all agreed that there were differences in the type of media (image, video or text), the kind of event depicted (intoxication, nudeness, racism, stupidity) and the scope of the consequences the online debut this content had (i.e. getting laughed at, being fired or getting arrested), we could not create an exhaustive topology of the different embarrassing content we found online. There seemed to be no key concepts that covered the scope of our phenomenon, nor were there any fitting theoretical frameworks.
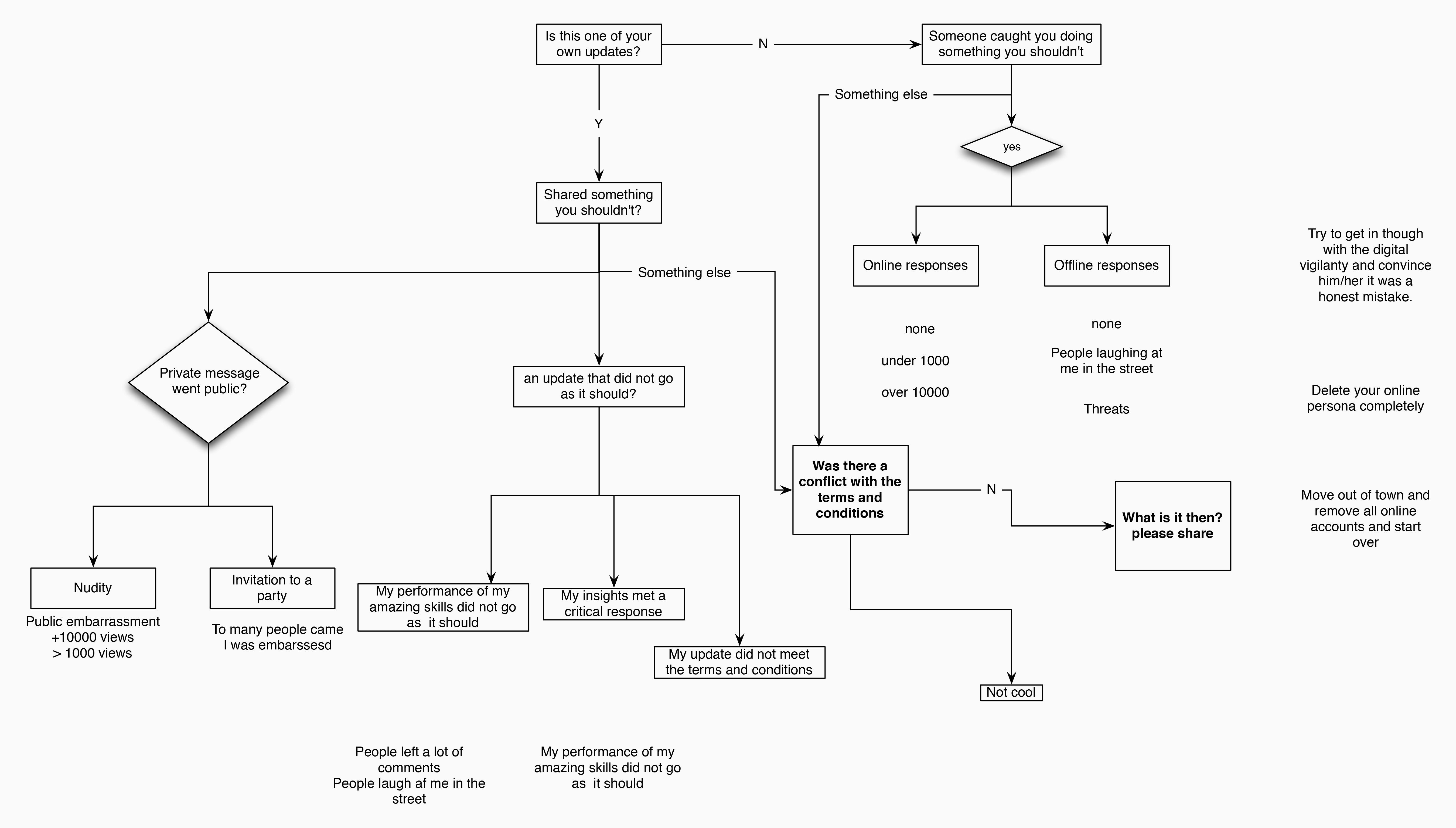
Figure 1: Schematic version of our original “digital hangover” test (click to enlarge)
As a result, we decided to shift the focus of our project away from describing different types of hangovers and towards examining frameworks and concepts with which the “digital hangover” could be conceptualized. As we tried to trace the many manifestations of the digital hangover, it quickly became apparent that static, linear academic frameworks were not dynamic enough to capture such a phenomenon that is still constantly taking on new shapes. Therefore, we decided to create an open platform through which emergent new media phenomena are observed and captured from a variety of complementary perspectives in a non-linear way, of which the “digital hangover” was a case study that we already filled in as much as we could. Like a wiki, our website allows people to add, modify, or delete content in collaboration with others and without a defined owner or leader. Currently afforded types of contributions are divided into the following categories: Concepts and Theoretical Frameworks; Tools, Techniques and Devices; Documented Examples and Case Studies; Relevant Projects; Research Questions, and Bibliographic References. These multiple perspectives may contain textual reflections and additional media such as images and video. In this way, the structure of the descriptions emerges according to the qualities of the project and its contributors.
The open platform accommodates in the “messy” phase of doing research when a phenomena is clearly emerging and is gradually shaped into form, but is not yet stable enough to be defined, demarcated and studied. Through new media technology, this platform aims to deal creatively with this problem by leveraging the eyes of the many. The platform thus introduces descriptive kind of research practice: a form of academically-oriented research that incorporates practice in the methodology of the research process. (To emphasize: this means that the larger idea of the site is that other emerging phenomena can also be studied here, but that we used the case of the “digital hangover” as a starting point).
2. Theorizing the “Digital Hangover”
Contrary to what the term “digital hangover” might suggest, we use this term to refer to more than just the embarrassing digital aftermath of a bad night spent drunk. Rather, the point is that a series of technical and societal shifts generate the potential for every object in a networked environment to travel and become something it maybe was not initially meant to be, and which can result in a haunting digital past (Tremlett 2013; Huhn 2005). We argue that this phenomenon cannot be reduced and isolated as either a social one, or a technical one. It also won’t suffice to say that the phenomenon is embedded in a broader context, for if that would be true, one could also dis-embed it and end up with the isolated phenomenon (cf. Wise 2005, 80). Rather, it requires us to engage with the complex and specific interplays between the two dimensions of this assemblage (Deleuze and Guattari 2008; Savage 2009).
The structure of the contextualisation that follows is divided into the brief discussion of three conditions and their implications. A first condition of the ‘digital hangover’ as media object we discuss is its ‘networkedness’. The argument is that media objects are necessarily networked, both metaphorically on the level of the social, and technically on the level of systems. A second condition discussed here is the condition of storage and remembering. In this part we discuss how stored media objects have a social life, because they have become part of everyday practices as much as they are part of archival practices. A third condition is that of encoding, which entails the recording, registration or appropriation of the media object into a networked space.
2.1 The Networked Condition of Media Objects
As a first condition of possibility, “digital hangovers” fundamentally require media objects to be networked.Their impact depends on the relations they produce, maintain and break to other objects, actors and systems: if no-one can know about the existence of the media object, that is, if it exists in isolation, then there is no reason for it to be embarrassing at all. Therefore, ‘networkedness’ constitutes a fundamental property of the “digital hangover.” We can think about the establishment of this networked condition from two perspectives.
First, we can think of it technically, for instance by considering how particular systems operate to automatically link objects to each other, or how systems afford manual linking of objects. As Stone et al. (2008) have shown, automatic face recognition might automatically embed people into the social graph based on personal photographs. The accuracy of this kind of annotation depends on the context of the media object, and might consist of metadata, GPS coordinates, comments, or related and close friendship links. Autotagging thus becomes a way of indexing the social graph, by systematically locating new media objects, assigning them a place in the formal system, and increasing their findability and usability by providing a basis for efficient access and lookups such as in a graph search. In a similar way, internet bots such as web crawlers used in search engine architectures systematically crawl the web to locate these media objects that are not yet embedded in the network graph (Kobayashi and Takeda 2000; Cho 2001; Gulli and Signorini 2005).
There are, then, a variety of types of automatic mechanisms that make sure that the internet remains a network, rather than just a big mess of dislocated documents, and they make use of metadata and annotative data in order to do so. On top of these automated mechanisms, there are also mechanisms that are implemented as platform features so that users themselves provide these links. Examples include friending, following, tagging people, or inviting friends to an event. These examples establishes that you are in a particular kind of relationship with someone else, and because it is at the same time a way of indexing the social graph, there are implications in terms of social status (e.g. which nodes constitute the influential hubs in a network).
Second, we can think of networkedness in a sociocultural way, for instance by considering the concept of cultural topology (Lury 2012; Lury et al. 2013; Phillips 2013). Celia Lury suggest that culture is becoming topological, which introduces a new order of spatio-temporal continuity for our lives today. This topological order emerges from our practices of sorting, naming, comparing, listing, ranking, calculating, and so on (Lury et al. 3). Indeed, indexing a social graph might be one example of this becoming topological of culture and society. This conceptual model is useful here because it offers a way to think about networks in terms of the distances between nodes in a graph. Intuitively, it seems that the shorter these distances will be, the higher the chance is that media objects will travel to that place. That is, it might be more likely that someone in your list of friends or followers will witness and spread your “digital hangover”, then it is for someone you don’t know to witness and spread it. In this model, highly visible people such as a politicians with lots of followers just have many more of those close relations. Closely related to cultural topology is the concepts of social diffusion (Rogers 1962; Sampson 2012; Tarde 1903), and that of memetics and meme theory (Dawkins [1976] 2006; Blackmore 2000; Mandoki 2005). These approaches show how this kind of diffusion through society can be understood in terms of biological metaphors taken up from evolutionary theory. The sociocultural perspective, as seen this way, mainly has to do with social and cultural habits and mechanisms that enable media objects to disperse through the network, but also to produce the sociocultural network.
2.2 The Social Life of Stored Media Objects
Another condition of possibility for “digital hangovers” is their remembrance by technological storage devices or in collective or individual human memory. Memory entails encoding or registration, storage and retrieval (recall), as well as forgetting, or the loss of memory. Furthermore, memory practices are bound up with questions of power and national narratives.
The traditional archive can be seen as both an object and a concept. As Jacques Derrida argues, the archive is intrinsically bound up with the forming of the nation state. The archive as institution was predominantly invented for governments to have a place to store and compare collected data about their citizens. This way, in case of war for instance, information about the amount of healthy young men that could be made into soldiers was readily available. Regular citizens had little to no access to this delineated form of the archive (Derrida 1998). Furthermore, as Michel Foucault states, archives are also a place of in- and exclusion and can therefore be seen in a more conceptual way. In traditional archives, this power mostly lays with governmental organizations that shape our notion of the collective memory by including certain documents and events in the archive whilst excluding others. Thereby, they are actively directing what is to be remembered and what is to be forgotten (Foucault 1982).
This traditional notion of the archive as delineated space with a top-down power structure changes with the advent of new media technologies that make it possible for people to make their own archives. In his text “Archive” (2006), Mike Featherstone reflects on how the everyday and the archive have gradually come to overlap: “Increasingly the boundaries between the archive and everyday life become blurred through digital recording and storage technologies. Not only does the volume of recordable archive material increase dramatically (e.g. the Internet), but the volume of material seen worthy of archiving increases too, as the criteria of what can, or should be archived expands. “Life increasingly becomes lived in the shadow of the archive” (Featherstone 591). This view, however, still takes archiving as distinct from the everyday practices. Below, we will offer a view that considers archiving to be part of the everyday practices themselves. Preservation, understood in terms of replication, becomes a by-product of the everyday use of digital devices themselves.
Technological storage devices typically resist deletion or forgetting, in favor of permanently storing just about everything they can. This is not just because hard drives are cheap, but also because networking and storage seem to necessarily go hand in hand. Networking and the distribution of media objects on the Web technically means for a file to be downloaded from one hard drive to another. A request to view a media object is also a request to download it onto another hard drive. This means that distribution and storage in a way have become the same thing, which is a complete overturn when considering the traditional archive, where unique objects are carefully preserved.
As a second point, some systems also help storing copies through their automatic operations. For example, whenever one posts a link to an object (or the object itself, for that matter) on Facebook, a thumbnail (read copy) is generated to go with that link. Another example might be the cached copies of media objects that Google Search crawlers keep for later processing or indexing and which can be viewed even when the concerned website itself has been taken down. The same object can thus come to exist in different sizes and resolutions. One can see this kind of archiving as well when searching by image on Google and selecting “Find other sizes of this image” (which is only possible because of prior processes of indexing). Each of these automatic mechanisms thus seem to resist forgetting, because you cannot simply destroy the one copy, you need to locate and destroy all of them. Consequently, the scope of the issue increases by an order of magnitude.
This “will to archive,” as Mike Featherstone calls it, leads to conflicts between storage and access: “With regard to storage, should the focus be on received traditions and the canon, or on local knowledge and diversity? How are decisions on what to collect, what to store, what to throw away and what to catalogue to be made? Today this is not just a question of which material to put on shelves in the stack and which to leave in unlabelled boxes in the backrooms, but how to deal with potentially unstable electronic archives (593).”
This then also brings to the fore a second characteristic: archives and databases are not kept and accessed only by a small minority and only after a fair amount of time has passed. Rather, they are horizontally explored and part of many practices of everyday use (for instance by the systems mentioned above). In a horizontal experience of the archive, time is reduced to a metadata property. When moving from one video on YouTube to another, the time on which that video was uploaded or even recorded is completely irrelevant. David Beer and Roger Burrows write about this as the “social life of data”, which refers to the performative implications resulting from the circulation of data. As they argue:
We might reasonably conclude that routine everyday engagements with popular culture, facilitated by technological and cultural transformations, are responsible for affording the accumulation of vast by-product datasets that can be conceptualized through a notion of archives and archiving. Similarly, we might also reasonably conclude that this data has a life after its harvesting, it has a social life as it finds a new vitality through the play of individuals and through the excitement of participation, and that in some instances it feeds directly and indirectly back into the organization and relations of popular culture. These feedback loops can be knowing and active or unknowing and algorithmic. (Beer and Burrows 67)
The implication of this “social life” of media objects is that the object will never really be forgotten, instantiating the hangover that never ends and is only repeatedly renewed.
2.3 The Encoding, Registration and Appropriation of Media Objects
A third condition of possibility, preceding storage, are the practices of encoding, registration and appropriation. Although conceived of as such in the nineties, the online and the offline have never been two separate realms. Over the recent years, their overlapping has become increasingly visible. The “digital hangover” does not come from the Web, but is transported to it from physical (offline) spaces by digital recording devices varying from security camera systems to mobile phones and sensors. Wherever there are people, there are most likely also recording devices around. As a result, the “digital hangover” is often not the product of your own stupidity (e.g. sending an embarrassing message to someone), but is usually the result of someone elses witnessing or recording. A friend, for instance, might upload a photo to his or her Facebook profile in which he or she might tag you, but which you would rather not be associated with. This is especially the case for highly visible people that often have camera’s on them, such as politicians and tv-personalities.
Practices of appropriation take media objects that are already out there and dis-embed these from their original contexts in order to give them a new meaning. The contents of a video recording might be appropriated and end up as a GIF or a still with text superimposed on it. Appropriation is similar to registration, because new content is created that produces the ‘digital hangover’ or makes it even worse. When someone appropriates a media object, the “digital hangover” is not just replicated as yet another copy, but is “affirmed” by the appropriation as well, that is, it is recognised as such.
Automatic practices of registration may be of less relevance here, but are present nevertheless. Camera systems in public space, hidden camera’s at home, and other situations where the recording devices are not always consciously acknowledged can be a source of “digital hangovers” as well. But as the term “hangover” seems to imply, it does take a human to go over this automatically recorded material in order to spot the embarrassing element. That is, what exactly is considered to be embarrassing is culturally sensitive. Interestingly enough, however, recently announced wearable devices with recording capabilities like Google Glass, Autographer or Memoto might take this to a whole new level, because the person will know when something embarrassing happens in front of their Glass. The argument that can be made in relation to both examples is that it has become impossible to remain outside of the “viral circuitry” of embarrassing media objects.
Consequently, some artists and activists have started thinking about the tactical possibilities in such a condition. As an example, the Web 2.0 Suicide Machine (2009) is a service that helps users to automatically remove their private content and relationships. The operations of the systems are identified, and exploited for purposes other than those intended. Yet, deleting private content and relationships usually only covers part of the problem, because the problem itself seems to be networked and resilient. Whenever you try to point and delete new variations will pop up, often even in reaction to this attempted removal.
Conclusion
Although much more is to be said and studied about any of the conditions identified above, our aim has been to briefly identify and discuss some fundamental conditions of possibility of the phenomenon that we have termed the “digital hangover”. First, “networkedness” has been identified as a condition, which was discussed both as technical and a sociocultural condition. Second, the notion of the archive is changing with new media technologies, and media objects and data more generally tend to have a “social life” (Beer and Burrows 2013). The archive is alive, or rather the act of archiving has in a way become a by-product of everyday technological and cultural practices. Third, encoding practices have been identified as another condition of possibility for the “digital hangover”. Recording devices, systems and techniques seem to become increasingly more present and ubiquitous, but the implications of this remain unclear.
The three conditions that we have identified offer broad ways to think about what makes the “digital hangover” historically and conceptually meaningful, and allow for it’s implications to be studied in more detail. The stakes are not just technological, nor are they simply a matter of dominant mindsets. Rather, a complex play of socio-technical dynamics becomes constitutive of the experience of our present everyday lives with new media, and this includes dealing with the “digital hangover” some of us might have experienced.
About the Project
DigitalObservatory has been developed by Bart Schoenmakers, Fernando van der Vlist, Ihab Khiri, Katja Vershinina, May Andersen, and Tessa de Keijser. We are a group of Master students in New Media and Digital Culture at the University of Amsterdam, where this project was initially conceived in October 2013.
References
Beer, David, and Roger Burrows. “Popular Culture, Digital Archives and the New Social Life of Data.” Theory, Culture & Society 30.4 (2013): 47–71. Print.
Blackmore, Susan. The Meme Machine. Oxford: Oxford University Press, 2000. Print.
Cho, Junghoo. “Crawling the Web: Discovery and Maintenance of Large-Scale Web Data.” Stanford University, 2001. Print.
Dawkins, Richard. “Memes: The New Replicators.” The Selfish Gene. Oxford: Oxford University Press, 2006. 189–201. Print.
Deleuze, Gilles, and Félix Guattari. “Balance Sheet for ‘Desiring-Machines’.” Chaosophy: Texts and Interviews: 1972-1977. Ed. Sylvère Lotringer, Trans. David L Sweet, Jarred Becker, & Taylor Adkins. Los Angeles: Semiotext(e), 2008. 90–115. Print.
Derrida, Jacques. Archive Fever: a Freudian Impression. Chicago: University of Chicago Press, 1998. Print.
Featherstone, Mike. “Archive.” Theory, Culture & Society 23.2-3 (2006): 591–596. Print.
Finin, Tim et al. “The Information Ecology of Social Media and Online Communities.” AI Magazine 29.3 (2008): 77–92. Print.
Foucault, Michel, and Alan Sheridan. The Archaeology of Knowledge; and the Discourse on Language. New York: Pantheon Books, 1982. Print.
Gulli, A, and A Signorini. “The Indexable Web Is More Than 11.5 Billion Pages.” WWW 2005 (2005): 902–903. Print.
Huhn, Mary. “Texting Under Influence – High-Tech Hangovers Haunt Gadget Geeks; Call It TUI – Texting Under the Influence.” New York Post. 21 Apr. 2005. Web. 17 Oct. 2013. <http://nypost.com/2005/04/21/texting-under-the-influence-high-tech-hangovers-haunt-gadget-geeks-call-it-tui-texting-under-the-influence/>.
Kobayashi, Mei, and Koichi Takeda. “Information Retrieval on the Web.” ACM Computing Surveys (CSUR) 32.2 (2000): 144–173. Print.
Luksch, Manu, and Mukul Patel. “The Filmmaker as Symbiont: Opportunistic Infections of the Surveillance Apparatus.” Ambienttv.net, 2006. Web. 17 Oct. 2013. <http://www.ambienttv.net/content/?q=dpamanifesto>.
Lury, Celia, Luciana Parisi, and Tiziana Terranova. “Introduction: The Becoming Topological of Culture.” Theory, Culture & Society 29.4-5 (2012): 3–35. Print.
—. “Topological Sense-Making: Walking the Mobius Strip From Cultural Topology to Topological Culture.” Space and Culture 16.2 (2013): 128–132. Print.
Mandoki, Katya. “Social Contagion and the Concept of Cultrome: Biomedical Metaphors in Understanding Culture.” Ometeca 10 (2005): 41–50. Print.
Phillips, John W P. “On Topology.” Theory, Culture & Society 30.5 (2013): 122–152. Print.
Rogers, Everett M. Diffusion of Innovations. Glencoe: Free Press, 1962. Print.
Savage, Mike. “Contemporary Sociology and the Challenge of Descriptive Assemblage.” European Journal of Social Theory 12.1 (2009): 155–174. Print.
Stone, Zak, Todd Zickler, and Trevor Darrell. “Autotagging Facebook: Social Network Context Improves Photo Annotation.” Computer Vision and Pattern Recognition Workshops, 2008 (CVPRW ‘08) (2008): 1–8. Print.
Tarde, Gabriel. The Laws of Imitation. New York, NY: Henry Holt and Company, 1903. Print.
Thelwall, Mike, Liwen Vaughan, and Lennart Björneborn. “Webometrics.” Information 39.1 (2006): 82–135. Print.
Tremlett, Giles. “Caught in the Web: Case Histories Of people Whose Digital Past Haunts Them.” The Guardian. 4 Apr. 2013. Web. 17 Oct. 2013. <http://www.theguardian.com/technology/2013/apr/04/web-case-histories-digital-past>.
“Web 2.0 Suicide Machine.” Wikipedia, the free encyclopedia. Wikimedia Foundation, Inc., n.d. Web. 17 Oct. 2013. <http://en.wikipedia.org/wiki/Web_2.0_Suicide_Machine>.
Wise, J Macgregor. “Assemblage.” Gilles Deleuze: Key Concepts. Ed. Charles Stivale. Montreal/Kingston: McGill-Queen’s University Press, 2005. 77–87. Print.