Spy me, please!
A project, brought to you by Afra Suci Ramadhon, Alina Niemann, Kimberly Leerkes, Kyra Teklu and Radina Teodosieva
The exhibitionist beginning
Several weeks ago we were presented with an assignment - to create a new media project, intervening an ongoing academic or public debate. After our initial struggles to come up with an interesting and doable idea, we decided to create a playful new media object, which is situated in the privacy debate and monetary politics of big data companies.

Spy me, please! logo
It is an intervention: who wants to be spied on and why?
The ironic title of our project is “Spy me, please!”. The name is related both to the debates in which it intervenes, but also to the idea that when someone creates a profile in social media, he actually allows companies to spy on him. Our project’s aim is to create awareness about the amount of personal information that is gathered by big IT companies, so that people can make responsible and informative choice, when using social media and digital services.
The information age brought new challenges related to the digital culture. Information and personal data are transformed into money by the IT companies. Big digital businesses profit from their user’s data not only by selling it but through target advertising, profiling and data mining (M. Ziegele and O. Quiring, 182). In that way actually the user is paying for the free service with his personal information, which makes the privacy debate very important and relevant. Castells thinks of privacy as the control over someone’s reputation (what people know about the user) (Howard, 5). Agre continues the idea with the notion that losing privacy means losing identity (Agre, 738). Lessig argues that personal aggregated data is more important to the business model of IT companies than to the state’s surveillance (Lessig, 202). Because of the financial incentive for the IT companies the online privacy of users is under threat of violation with every new media object or service. When creating a Facebook or Google account, the user is accepting their Terms and Conditions, which many times state that the user is giving the company and third parties the license to use the data from the profile and the amount of data (content included) created during the exploitation of the services. So data collection and aggregation is at the core of online services. That is the reason for many privacy violations lawsuits against digital giants like Google, Apple and Facebook. Predominantly the claims are for lack of transparency of their big data business model.
Self-spying?
After we came up with the goal and the field of intervention, we started thinking about concept and realization. We decided to take the pedagogical view and educate users through mobile application. So the concept of our project was to show users how much data can be extracted from their profile and online activities.
We begin our practical work with initial research into the big data business model and its transparency. Additionally, we looked at the options of tracking in terms of amount of data and its variety. To limit the scope of the investigation into how much and what user’s data companies collect and what information really can be collected, we focused on Google as one of the companies with worst privacy practices (Simpson, 2007). We decided to compare the statistics from the tools that Google provides for self-tracking (history of Google Chrome and Dashboard) and independent products like data loggers, website monitoring tools and traffic analysis tools, which later will be used for our app’s algorithms. We chose Kidlogger and Qustodio, freemium applications for parents to track their kids. The result was definitive.
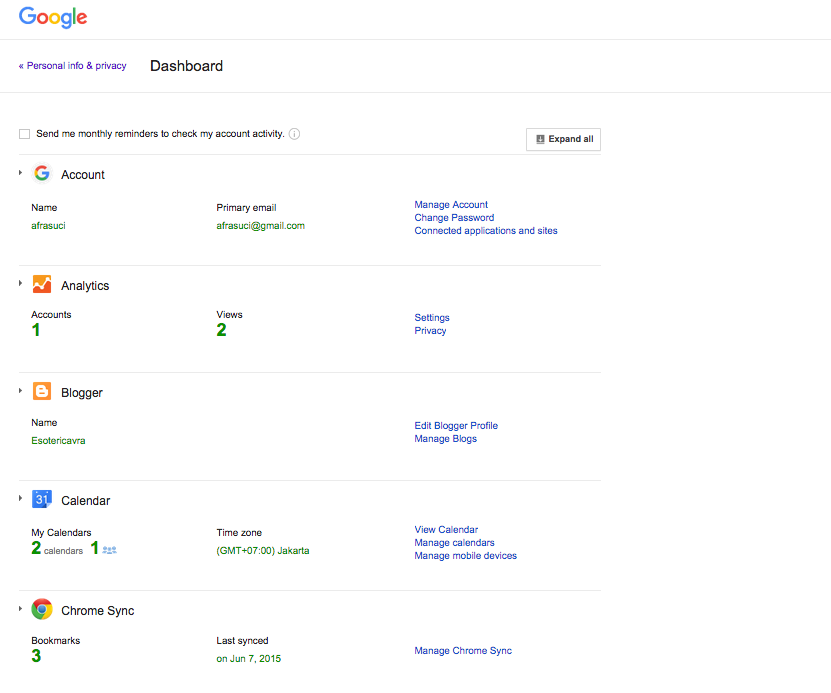
Screenshot of Google Dashboard results
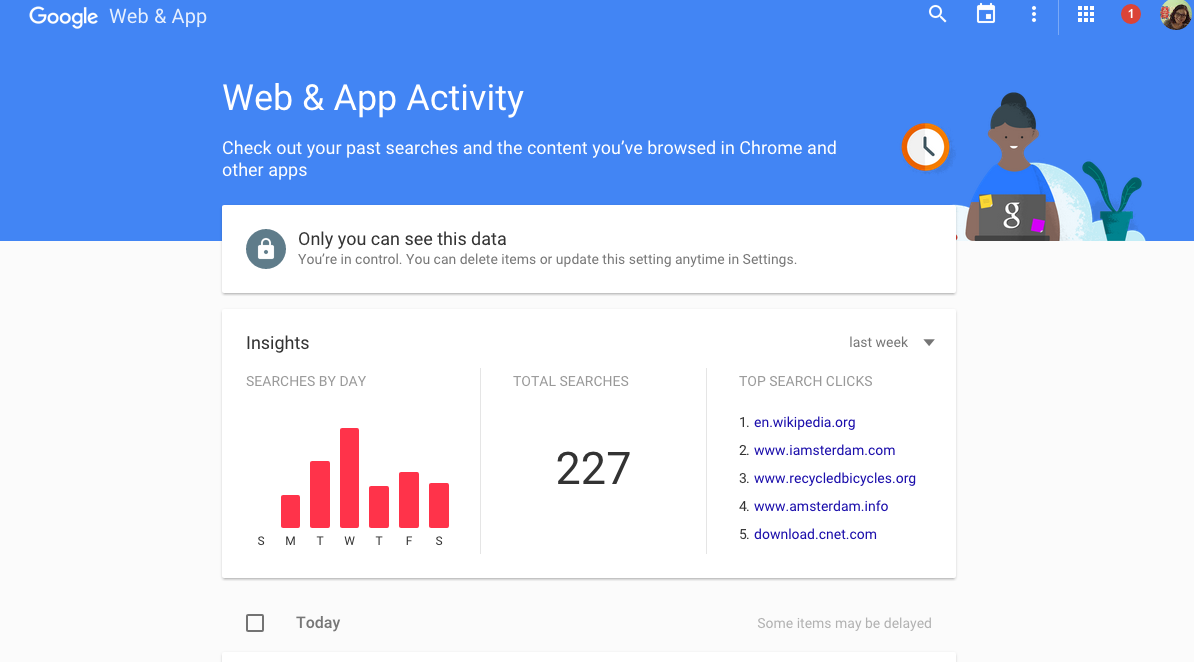
Screenshot of Google History results
Results from Qustodio and Kidlogger
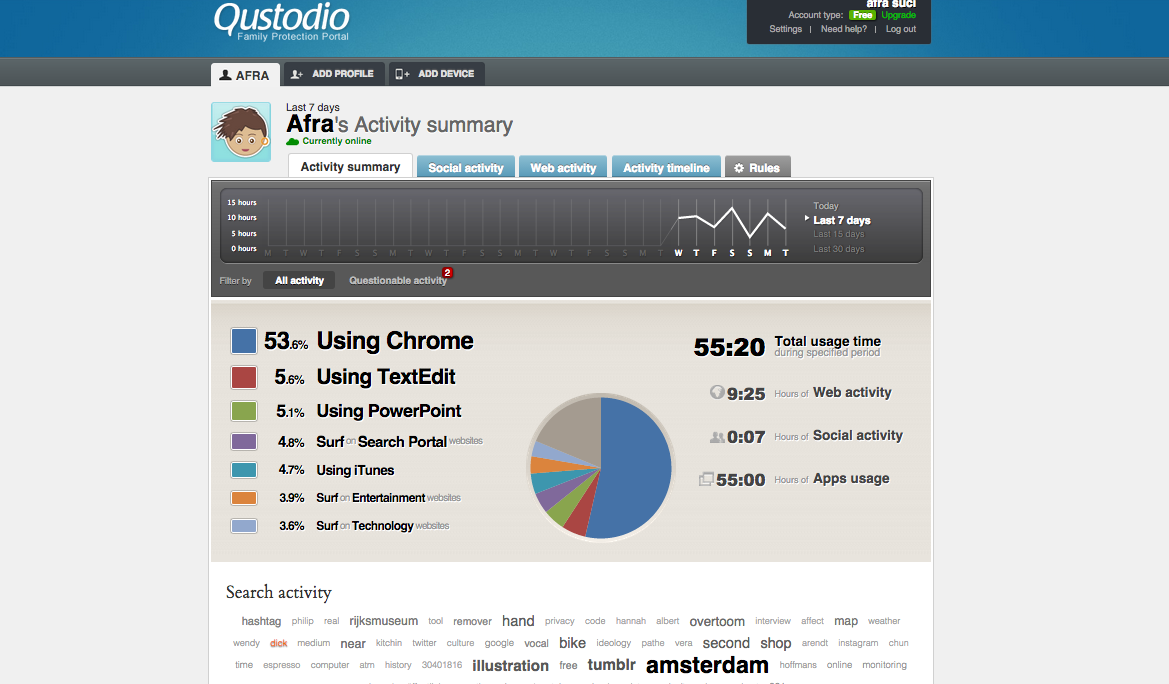
Screenshot of the Qustodio results
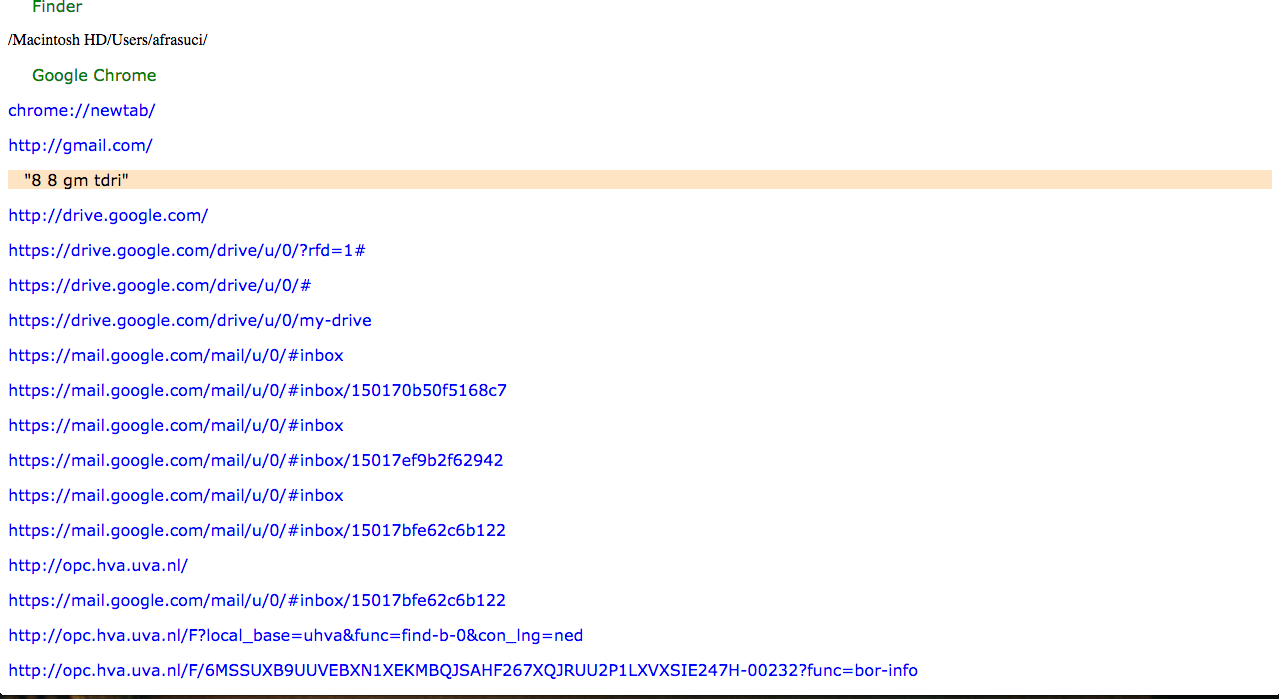
Screenshot of Kidlogger results
The amount and variety of information, represented on Dashboard, were insignificant compared to the reviews from Kidlogger and Qustodio, which showed screenshots and alarmed for questionable searches. We were intimidated by the options of tracking user’s digital trail. Our results showed us the importance of transparency and the ultimate goal of our app – users making responsible decisions for their online behavior through awareness of the amount and variety of information that can be collected from it and the consequences of that on their life and privacy.
How it works
So we created a clickable prototype of the “Spy me, please” app with all the necessary functions. We used Adobe Photoshop and Marvel App to create a slick and easy-to-use design with clear and simple interface so that the user isn’t disturbed or distracted and can quickly access and review the findings of his self-spying.
First, the user should sign up and leave information about his accounts on the Internet, so that the app can work. Then he can check different aspects of his online activities.
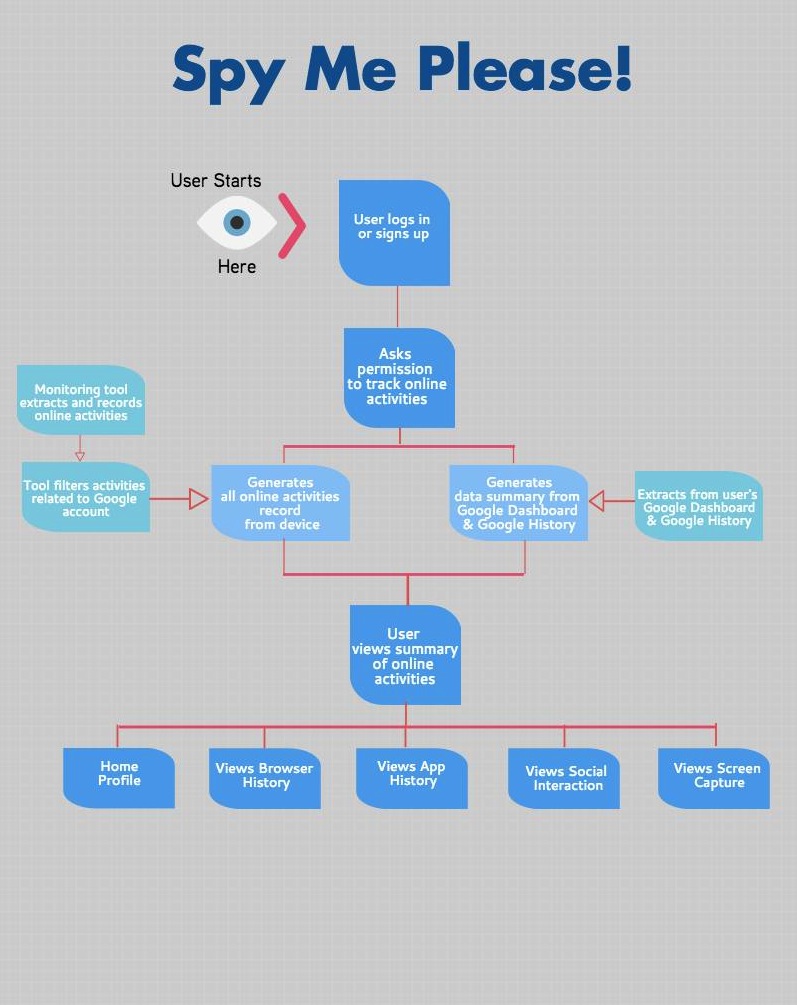
Flowchart of the working app
The browser history shows a summary of every click, which the user made with beautiful visualization and statistics for more comprehensive view of the amount of data, which was collected. Moreover, the user can actually see the browser summary for his different devices – laptop or desktop computer, tablet and smartphone.

Browser History Menu
The app history menu represents the time spent on different platforms like Facebook, Instagram, Youtube and Skype. The social interaction section of the app shows an overview of the user’s contacts and history of chats and calls, even the deleted ones. The app gives information how it collects data. Furthermore, the user can track his social interactions on different platforms such as Facebook, Google +, WhatsApp and Skype. The screen capture menu shows the screenshots, which were taken by the app and the exact time.
User experience
To complete our pedagogical goal the user should go through several steps using our app. Firstly, the user is shown the amount and variety of data, which is collected by the app from his online activities, so that he is aware of how much different personal data can be gathered and owned by IT companies, which they will not disclose. Here, the educational process starts with the realization of the privacy issue, related to the big data business model and the tracking options of software. Secondly, the user is gaining a sensitivity about these problems of the digital services. He is realizing that he pays for e-mails, social media and e-services with his personal details. In the end, the user is provided with sufficient information, so that he can make responsible choices for his online behavior. He becomes educated about privacy and big data business model and starts browsing the Internet cautiously. That is the reason to target our project to everyone who is using social media and online services.
The future of “Spy me, please!”
To sum up, “Spy me, please!” is a playful intervention into the privacy debate. Our project always will be relevant, because with every new online service or social network, privacy issues will arise. The ideal aim is for “Spy me, please!” to be a step further into the media literacy education, which will turn users of Internet into aware participants in the digital culture.
You can follow our project and see our research results on our Tumblr: http://spymeplease.tumblr.com/
References:
Agre, Philip. “Surveillance and Capture: Two Models of Privacy.” The New Media Theory Reader. Eds. Noah Wardrip-Fruin and Nick Monfort. Cambridge MA: MIT Press, 2003. pp. 737-760.
Gibbs, Samuel. “Class Action Privacy Lawsuit Filed against Facebook in Austria”. The Guardian. 9 April 2015. 15 October 2015. <http://www.theguardian.com/technology/2015/apr/09/class-action-privacy-lawsuit-filed-against-facebook-in-austria>.
“Google Terms of Service – Privacy & Terms”. Google. 15 October 2015. <http://www.google.com/intl/en/policies/terms/>.
“Google Privacy Policy – Privacy and Terms.” Google. 15 October 2015. <http://www.google.com/policies/privacy/>.
Howard, Philip N. Castells and the Media: Theory and Media. First edition: Polity, 2011.
Lessig, Lawrence. “The Architecture of Privacy.” Taiwan Net ’98 conference, Taipei, March, 1998.
Piper, Paul S. “Google and Privacy.” Internet Reference Services Quarterly. 10. 3-4 (2005): 195–203.
Reed, Brad. “Apple Privacy Lawsuit: Judge Calls Company Untrustworthy”. BGR. 8 March 2013. 15 October 2015. <http://bgr.com/2013/03/08/apple-privacy-lawsuit-364252/>.
Simpson, Gemma. “Google Scores Lowest in Privacy Rankings.” ZDNet. 2007. 15 October 2015. <http://www.zdnet.com/article/google-scores-lowest-in-privacy-rankings/>.
Williams-Grut, Oscar. “Do You Use Safari? You Could Have the Right to Sue Google for Snooping”. The Independent. 27 March 2015. 15 October 2015. <http://www.independent.co.uk/news/business/news/google-faced-with-privacy-lawsuits-for-snooping-on-apple-users-without-consent-10138944.html>.
Ziegele, Marc and Oliver Quiring. “Privacy in Social Network Sites.” Privacy Online. Perspectives on Privacy and Self-Disclosure in the Social Web. Eds. Sabine Trepte and Leonard Reinecke. Berlin, Heidelberg: Springer-Verlag, 2011. pp. 175 – 190.