Facebook’s Rosetta: How Are Algorithms Using Our Data?
Digital networking companies have started to build artificial intelligence software that can filter through unwanted content that may be offensive to their users. Facebook recently announced the latest addition to this trend with a machine learning program called Rosetta; software that can analyze photos and videos that contain text. The purpose of Rosetta is to help Facebook automatically detect content that violates the companies hate speech policy. The social network also released an explanation of how the algorithm works (below).
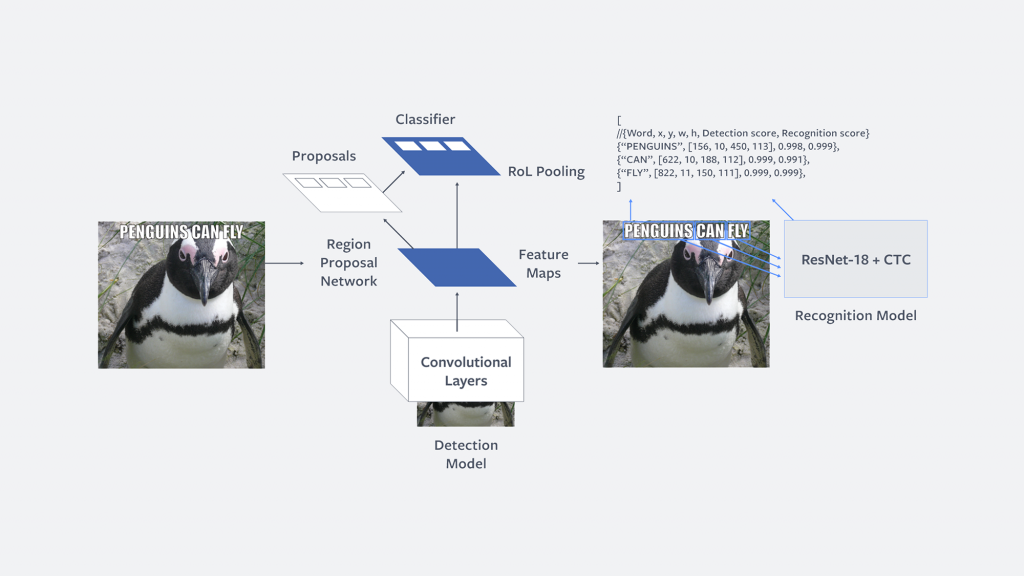
When introducing Rosetta, Facebook announced that the software can process one billion public images and videos uploaded each day. Rosetta works through a two-step model: detecting and recognizing. The former scans for images that may contain offensive text and the latter determines what the text in the image or video actually is. The algorithm behind Rosetta is instructed to flag certain text that may be offensive, particularly in memes circulated on the platform. Along with removing offensive content, Rosetta works on both Facebook and Instagram to make images appear under both the ‘explore’ and ‘search’ pages, as well as determine how the content should appear on the News Feed.
Rosetta was built to function as a system that can contextualize writing found within images of videos, which requires an algorithm with predictive capabilities. Therefore, Rosetta works as a process of machine learning with programmed objectives that utilize data and math to figure out what factors will contribute to its final goal. The algorithm is formed by a process of self-learning where it works its way step-by-step towards the desired outcome by attempting several different methods. Rosetta will therefore flag inappropriate content, and if it has mistakenly marked text as spam or offensive, it will rework its method for future analysis.
Machine learning programs, such as that used by Rosetta, exemplify the sociopolitical issues that may arise with emerging new media. This app automates the process of verifying whether content on Facebook is deemed as appropriate and should be allowed to remain on the platform. In the past, flagging inappropriate content on Facebook was a task for human labour, however the emergence of algorithmic systems has replaced human decision-making with mechanically programmed reasoning. David Chandler (2015) argues that algorithms which try to calculate and control human needs, through the use of Big Data, promise a post-human world, where “‘data’ do the work,” as opposed to humans. The reason the infrastructure behind Rosetta needs to be investigated is to uncover the underlying social consequences of implementing machine learning that reviews unethical uses of Facebook (Star 1999).
Big Data and Algorithmic Detection
Machine learning would not function without the systematic collection of millions of users online data. Once data is collected it becomes an input that is used by algorithms to produce an output (Burrell 2016). However, the process in between the initial input and final output are unknown to those who own the data in which these algorithms operate on. In terms of Rosetta, there is no way for Facebook users to opt-out of these algorithms analyzing their content and collecting data from what they post online. Therefore, It is important to understand what happens to our data once posted, and what algorithms are used to manipulate this data. For any collection of personal data, users should understand the privacy concerns associated with the circulation of personal information.
By definition, machine learning is created in order to discriminate by identifying useful patterns in data. This creates problems as users are asked to blindly trust the algorithms which manipulate their data (Veale & Binns 2017). Algorithms that are built to distinguish between right and wrong should not always be trusted as they do not have affects, ethics and morals and only act based on programmed instrumental logic (Fuchs 2017). Since machines are told what they should define as appropriate, they are unable to make neutral decisions when measuring fairness (Veale & Binns 2017). As Christian Fuchs (2017) Points out, with the use of big data, algorithms make choices on behalf of humans and make assumptions about human behaviour based on linear logic. Relying on algorithmic logic which can be prone to errors, will most likely create false positives and flag content that may have been marked appropriate by a human mediator (Fuchs 2017). Rosetta has led Facebook to delete some accounts that have been flagged as violent, which means an error in data analysis could affect any potential users if the algorithm improperly detects information.
Algorithmic Opacity
On the other hand, there are cases where publishing algorithms has led to the mis-use of such technology, challenging whether companies should really be transparent with these systems. Previous algorithms have run into difficulties when they were set to detect and rate the severity of offensive content. An example of this occurred when Google deployed an artificial intelligence system to detect hate comments. After Google’s algorithm was made public, users undermined the technology by tricking it with typing errors and spaces in between the words so their comments could remain undetected. In a similar case, after Rosetta was announced by Facebook a group called QAnon was determined to show their followers that they could disrupt the algorithmic detection process. QAnon created memes and videos with obscured fonts and texts in order to trick Rosetta’s system.
Conclusion
Facebook’s release of Rosetta may possess several potential problems. By making the algorithm public, Facebook has faced challenges with users finding ways to work around the systems detection processes. Yet, it is still important for large corporations to make the infrastructure visible and understandable to its users as it analyzes content that they post. Whether content is appropriate for Facebook or not is probably better determined by a human than a machine, but understandably, the process costs less and uses less time when programmed. In order to make sense of what happens to our data after it is collected by such systems, algorithmic infrastructures must be unlocked from the black box. In the end, active digital users have more to lose from the misuse of our data than multi-billion dollar corporations do from the misuse of their algorithms.
Work Cited
Burrell, Jenna. “How the Machine Thinks: Understanding Opacity in Machine Learning Algorithms.” Big Data & Society, vol. 3, no. 1, 6 Jan. 2016, doi:10.2139/ssrn.2660674.
Chandler, David. “A World without Causation: Big Data and the Coming of Age of Posthumanism.” Millennium: Journal of International Studies, vol. 43, no. 3, 2015, pp. 833–851., doi:10.1177/0305829815576817.
Deutscher, Maria. “Facebook Has Built an AI Called Rosetta to Analyze 1B User Images a Day.” SiliconANGLE, 11 Sept. 2018, siliconangle.com/2018/09/11/facebook-built-ai-called-rosetta-analyze-1b-user-images-day/.
“Explaining AI.” Magnetic, Magnetic, www.magnetic.com/wp-content/uploads/Explaining-AI-eBook.pdf.
Fuchs, Christian. Social Media: a Critical Introduction. SAGE, 2017.
Matsakis, Louise. “Facebook’s AI Can Analyze Memes, but Can It Understand Them?” Wired, 14 Sept. 2018, www.wired.com/story/facebook-rosetta-ai-memes/.
Matsakis, Louise. “QAnon Is Trying to Trick Facebook’s Meme-Reading AI.” Wired, 18 Sept. 2018, www.wired.com/story/qanon-conspiracy-facebook-meme-ai/.
Smith, Adam. “Facebook’s Rosetta AI Detects Offensive Memes.” PCMAG, 12 Sept. 2018, www.pcmag.com/news/363683/facebooks-rosetta-ai-detects-offensive-memes.
Star, Susan Leigh. “The Ethnography of Infrastructure.” American Behavioral Scientist, vol. 43, no. 3, 1999, pp. 377–391., doi:10.1177/00027649921955326.
Veale, Michael, and Reuben Binns. “Fairer Machine Learning in the Real World: Mitigating Discrimination without Collecting Sensitive Data.” Big Data & Society, vol. 4, no. 2, 2017, doi:10.31235/osf.io/ustxg.