Am I—Reflections on the search recommendations, algorithmic identity and the datafied subject
“The endless, continuously updated streams of information online are selected, processed and made available through recommendations calculated by complex algorithms. Am I explores how these algorithmic recommendations shape our everyday existence – and both reflect as shape our sense of self. Am I explores how Google gets to know us – and in turn determines what there is to know about ourselves, and how to know it.”
– Introduction text of the ‘Am I’ exhibition
https://www.youtube.com/watch?v=rGCRnQelPcM
Figure 1. Video clip of Am I exhibition (CLICK IT!)
The importance of algorithms in our datafied world has become a widely discussed topic. More and more it is realised what crucial role they play in selecting what we get to see online. Algorithms are useful, of course, indispensable even; but since they are such a key feature of the information architecture of new media. Since ‘there is no such thing as “neutral” design’ (Thaler and Sunstein, 2008, p.3), interrogating how algorithms work, the underlying values of their programming and the consequences these choices have in shaping our culture are of growing relevance and urgency. In the above introduction text, we included an observation from Tarleton Gillespie, who stresses exactly this point. He observes that algorithms ‘not only help us find information, they provide a means to know what there is to know and how to know it’ (Gillespie, 2014, p.167). Gillespie offers us a starting point for
understanding the cultural and political consequences of what he calls public relevant algorithms, by taking apart their specific knowledge logic. He observes several knowledge logic dimensions, such as the way algorithms try to anticipate users behavior and the promise of algorithmic objectivity. A dimension relevant in the context of our project, is ‘the production of calculated publics’. This entails
‘.. how the algorithmic presentation of publics back to themselves shape a public’s sense of itself, and who is best positioned to benefit from that knowledge ’
– (Gillespie, 2014, p. 168).
This specific dimension of algorithmic knowledge production touches upon what John Cheney-Lippold has described as a process of algorithmic identification. His analysis firstly focuses on the ‘how’ of such a process, in which categorisation according to our user data play a crucial role. Certain patterns of online behavior leads to the assignment of ‘52% female’, for example. He emphasises that this identification process is continuously adapted on the basis of new data-inputs. The relevance of this process, that happens behind the ‘computational curtains’, is that they these identities inform the recommendations we get as users, such as ads. This way, our algorithmic identities present us with their interpretation who we are – in a selection of what we get to see. This mechanism can be seen as a technology of power, a form of control:
‘ Interpreting control’s mark on subjects as a guiding mechanism that opens and closes particular conditions of possibility that users can encounter. The feedback mechanism required in this guiding mechanism is the process of suggestion.’
– (Cheney-Lippold, 2011,p. 175)
By shaping the terms of our information, these suggestions shape the terms of our subjectivity; telling us who we are, what we want and who we should be. At the same time, the suggestions are based on our online behavior, on what we do, and are embedded within a broader cultural logic and knowledge system. This means that suggestions are both shaped by us and shape us; a beautiful example of the productive working of power as described by Foucault.
It is this process that we set out to research while developing Am I . And if one wants to interrogate the influence of algorithms on our subjectivity, what better place to start than one of the most used – and as much heralded as contested – algorithms; the Google search algorithm. There is much research into how the first search results are what most people click on – and how adapting these results can have huge consequences for how people think about certain issues and reinforce bias (see for example Epstein and Robertson, 2015, Noble, 2018). A specific feature of the Google search algorithm is the autocomplete recommendation that appears while a user is typing in a query. By not even letting us finish our thought, it already suggests what we might be looking for. Google explains that this feature is a ‘huge time saver’ which ‘reduces typing by about 25 percent’ on average:
‘ Cumulatively, we estimate it saves over 200 years of typing time per day. Yes, per day! ’ – from: “How Google Autocomplete Works in Search.”
Which means that the feature is indeed used a lot, and its role in selecting and then suggesting what information we might be looking for, has great significance. Google itself stresses it does not intends to steer us in any direction by the autocomplete feature, by explicitly noting that they should be read as ‘predictions’:
‘ You’ll notice we call these autocomplete “predictions” rather than “suggestions,” and there’s a good reason for that. Autocomplete is designed to help people complete a search they were intending to do, not to suggest new types of searches to be performed. These are our best predictions of the query you were likely to continue entering .’ from: “How Google Autocomplete Works in Search.”
Though Google seems to take distance from the effect of suggesting what we could search for, this play of words can of course not limit its actual productive power. Autocomplete, whether intended or not, works as a form of control described by Cheney-Lippold. What is furthermore interesting about the autocomplete feature, is that it feeds-back information it collects of searches quite directly to us. There is definitely a process of selection and curation that we cannot see or evaluate – but it is still an interesting moment where the inner workings of the algorithm exposes itself through showing us what in its logic qualifies as a ‘prediction’ of our behaviour.
For these specific characteristics – Google searches important place in the hierarchy of algorithms, autocomplete as a much used feature and an opening up of the feedback mechanism, it forms an excellent artifact for our research. Our central research question being:
‘How can we explore the shaping of subjectivity by the process of algorithmic identities through search recommendations from Google?’
Secondary questions we investigated were: How are we defined by what we search or – how does the search recommendation ‘conduct conduct’? What insights give the recommendations us in the shaping of our subjectivity? What do the recommendations say about us and what do they say about the algorithm? How are the recommendations personalised, or differ in different contexts and languages?
The operationalisation
In order to focus our project on the shaping of algorithmic identities through google search, our focus is specifically on what people search for about themselves. To start simply here: how does autocomplete ‘predict’ queries starting with ‘Am I…?’. With this as starting point, we created an Alphabet of Suggestion as central element of our inquiry.
Because Google search results are contextual – within every country there are different search trends, autocomplete gives us the opportunity how the selection of algorithmic information is culturally embedded, by exploring which suggestions come up in different languages. Several friends were approached to type in the alphabet within their country in their respective languages.
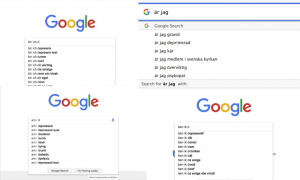
Figure 2. Searching in four different languages
We wanted to present this Alphabet in a way that would magnify the form of control of suggestions, to take these recommendations from the private, individual experience into a public experience, to offer a space for confrontation, contemplation and comparison. Exploring the Alphabet of Suggestions was fascinating. At the one hand it almost felt intrusive; many questions seemed to be very personal and private. At the other hand it seemed to offer a glimpse of what were more collective, cultural worries. This is how parallel to the conceptual axis of the power of the algorithmic recommendations in shaping our sense of self, a second axis arose: that of exposure of the personal. Searches that we made in the privacy of our own home, showing our personal doubts, vulnerabilities, are now out in the open. We turn to Google to ask things that we would never dare to ask to anybody; but Google sees it all and does not handle this information discretely; it shows it to everybody through its recommendations. To combine these different themes (how the recommendations shape of our subjectivity and culture while at the same time being embedded in that culture, the role of Google Search in intimate questions and the exposure of private information) we designed a multi-media art installation with three different elements.


Figure 3. Official webpage of Am I exhibition (Link: https://joyshijing.wixsite.com/amiexhibition)
The main, most central element of the installation are six huge pillars with the Alphabet of Recommendations projected on their side. Each side gives space to the recommendations belonging to one letter. People can go inside the pillars to further explore the alphabet, and because the sides are semi-translucent, visitors turn into dark silhouettes behind the autocomplete sentences. This creates the impression of both intimacy and exposure, of a person behind the questions, but a person without a face, simultaneously anonymous as utterly visible. The second element resides inside one of the pillars, and is a more interactive element. There visitors can find a personal search booth, with a Google search interface, and no possibility to go anywhere else. All the other information we might want to access, needs to be accessed through Google search. There is a choice however: either one can search using their own, personal log in, or a pre-programmed profile. This offers the possibility to compare their own results with the alphabet, which is also displayed inside the search booth. While a visitor is typing queries on the inside, these are projected on the pillar at the outside, exposed to the public. Everyone outside can see what the person is searching for and which autocomplete suggestions she sees. Just like the algorithm always ‘sees’ what we are doing, and feeds it back to public suggestions.

Figure 2. Overview of Am I exhibition
The final element revolves around the cultural context of searches and auto-correct. It is a video room where the prerecorded searches in different languages are simultaneously displayed. Under every screen there is an English translation available to compare the different results.
The installation gives time and space to reflect on key characteristics of a specific set of search results. Below, we explore some of the common characteristics of the autocomplete suggestions and what they tell us about a broader context, as well as how they might shape our subjectivity.
After the installation: reflections on autocomplete, algorithmic subjectivity and culture
If you type in the query ‘ Am I a…’ in Google search, you get a huge list of results. Strangely bragging about its performance, Google even clarifies that it found 485.000.000 results in 0,61 seconds. But only ten from these thousands of results are selected as autocomplete suggestions. In these autocomplete suggestions, some relevant results are highlighted while others excluded. It is algorithms that offer predictions about what you should or would be more interested to know. While algorithms were often described as being benign, neutral, or objective, they are anything but. (Noble, 2018, p.1). The search results could be influenced by geographic places, sponsors, national regulations and norms, and even way of expressions in the linguistic sense, both reflecting and reinforcing social logics (Stanfill, 2015). Therefore, on the one hand these personalized results are tightly bonded to cultural constraints. On the other, however, these auto-complete suggestions apply their own mathematical formulations to store, process, transmit these cultural issues and giving them new meaning by selecting the more ‘relevant’. Google search engine, in this sense, is capable to prioritize the searching results on the basis of a variety of topics that seem “objective” and “popular” (Noble, 2018, p.24).
When entering our art exhibition, you might immediately confront with this constructive power that “enable and assign meaningfulness, managing how information is perceived by users, the distribution of the sensible” (Langlois, 2012). To elaborate it more specifically, we extract some examples from our alphabet. All examples are collected from English language setting and private browsing model.
Am I: Beauty Matters
Throughout the whole alphabet, a large number of questions about appearance have been inquired via Google search. Instead of mentioning about other personal qualities, the importance of appearance is highlighted by Google autosuggestions. By constantly being suggested these questions a notice—if not anxiety—about one’s appearance has been made. It is worth mentioning that, the suggested beauty standards is not inherent or a quality that one was born with. Rather, every individual could give efforts to make some difference on the appearance throughout one’s lifespan. When one clicks one of the auto-complete suggestions, he or she would receive countless results offering articles, videos, and pictures about how to use specific makeups, clothing styles, or services to improve the personal atheistic image. By purchasing certain kind of commodities, one is promised to be more attractive. In this way, the beauty standard is transferred as a judgment of personal taste, which corresponds to certain commodities.
Am I attractive Am I beautiful
Am I cool
Am I fat or skinny Am I handsome
Am I: Know yourself through Quiz
Besides the forms of articles, videos, and pictures one might confront after clicking on certain search recommendation, there is another form to provide specific knowledge, which can be shown directly on the auto-complete suggestions—the quiz or test. As the following list shows, the questions linked to a quiz can be very soft. For instance, am I a good father. There should be no concrete answer to every quiz/test, but the quizzes/tests often use a quantitative method including questionnaires to measure the certain issues. It is hard to tell whether believe it or not, but this gamified way definitely opens up what can be quantitatively tested through this, which means that instead of different context for a different person, there is a standardized gradient suitable for everyone.
Am I a good father quiz
Am I a psychopath test
Am I addicted to cigarettes quiz Am I beautiful quiz
Am I depressed quiz
Am I evil quiz
Am I fat quiz
Am I gay quiz
Am I handsome picture test
Am I in love quiz
Conclusion
According to Halavais, a search engine is a window into our own desires, which can have an impact on the values of society (Noble, 2018, p.25). However, the purpose of Am I Exhibition is to reveal the fact that our desires and subjectivities have been gradually shaped in the process of autosuggestions by search engines. In other words, search engines like Google may to some extent defining who we are and what content we should see. Although Google stresses that its autosuggestion function is only a ‘huge time saver’ which ‘reduces typing by about 25 percent’ on average. It cannot be denied that certain values from specific kinds of people-namely, the most powerful institution in society and those who control them ((Noble 2018, p.29), have already embedded in our way of thinking, and shaping our subjectivities with or without consciousness. As Lacan described the process of completing one’s sense of
‘self’ is through the reflection of a mirror, and thus establish the relationship between the Innenwelt and the Umwelt (Lacan, 1949, p. 97). We believe that today search engine’s recommendation is increasingly shaping our subjectivities and has rather become the mirror for reflections of people’s ‘algorithmic identities’ than a ‘window’ into our own desires.
Bibliography
Cheney-Lippold, John. “A New Algorithmic Identity: Soft Biopolitics and the Modulation of
Control.” Theory, Culture & Society, vol. 28, no. 6, Nov. 2011, pp. 164–81.
Epstein, Robert, and Ronald E. Robertson. “The Search Engine Manipulation Effect (SEME) and Its Possible Impact on the Outcomes of Elections.” Proceedings of the National Academy of Sciences , vol. 112, no. 33, Aug. 2015, pp. E4512–21.
Gillespie, Tarleton. “The Relevance of Algorithms.” Media Technologies, edited by Tarleton Gillespie et al., The MIT Press, 2014, pp. 167–94.
“How Google Autocomplete Works in Search.” Google , 20 Apr. 2018, https://www.blog.google/products/search/how-google-autocomplete-works-search/ . Accessed 20 October 2018
Lovink, Geert. The Society of the Query and the Googlization of Our Lives . p. 7.
Safiya Umoja Noble author. Algorithms of Oppression: How Search Engines Reinforce Racism . New York University Press, 2018.
Lacan, Jacques, and Alan Sheridan. “The Mirror Stage as Formative of the Function of the I as Revealed in Psychoanalytic Experience.” Écrits: A Selection. London: Routledge, 2001. pp. 1-7
Langlois, Ganaele. “Participatory Culture and the New Governance of Communication: The Paradox of Participatory Media.” Television & New Media 14, no. 2, Mar. 2013, pp. 91–105. https://doi.org/10.1177/1527476411433519 .
Society of the Query | Reflect and Act! Introduction to the Society of the Query Reader. http://networkcultures.org/query/2014/04/23/reflect-and-act-introduction-to-the-society-of-t he-query-reader/ . Accessed 1 Oct. 2018.