Building a Feminist Dataset: Confronting algorithmic bias through the practice of thoughtful data collection
By Yan Cong, Kristen Zheng
Project idea
It is no news that algorithms can be sexist when autocompleting a sentence, performing facial recognition or displaying search results (Sheng et al. 2018; Buolamwini and Gebru 2018; Noble 2018). To confront this problem, artist and researcher Caroline Sinders (2020) started a multi-year project Feminist Data Set, to “interrogate every step of the AI process” (p.4) with the aim of designing a feminist chatbot. Currently the project has dealt with data collection and data labeling, the first two steps of the AI process.
Inspired by Sinders’ project, we follow the guideline in her project documentation to create a feminist dataset ourselves. Through this project, we seek to situate Sinders’ project in the current academic debate on algorithmic bias and data feminism. Both our research on existing literature, and the practice and reflection on data collection inform us to provide a critique on Feminist Data Set.
Current academic debate
Algorithmic bias
Algorithms can be simply understood as “a sequence of instructions telling a computer what to do” (Domingos 2015 cited in Brogan 2016). Unlike rule-based algorithms, in which the instructions are determined, machine learning algorithms write their own instructions based on given input and output data, through a mathematical process of “brute-force approximation” (Joler and Pasquinelli, 2020, p.11). The application of machine learning algorithms is in explosive growth due to the rising volume of data and increased computational power, the continuous innovation in image technology, video technology and human-computer interaction, and the increasing use of algorithm-based autonomous decision systems for data mining, search engines, biometrics and many other areas.
While some scholars take the social determinism view on algorithms and are optimistic about their neutrality (Cahn et.al., 2019), most scholars agree that algorithms are biased. Various examples of algorithms leading to gender and racial discrimination repeatedly demonstrate that the seemingly neutral, automated systems can produce unfair decisions and biased results (Danks, 2017). In other words, the existing biases in gender, race, ability and class in society are amplified by algorithms (Joler and Pasquinelli, 2020).
Existing research on the cause of algorithmic bias can mainly be summarized in threefold ways: First, the bias existing in the society before technological intervention; second, the bias related to the training dataset; third, the bias related to the algorithm model itself (Friedman and Nissenbaum, 1996; Baeza-Yates, 2016; Danks, 2017; Joler and Pasquinelli, 2020). This research project focuses on the process of building a training dataset, so we will review relevant research on the bias related to the training dataset below.
As the data used for training an algorithm is the cornerstone of the algorithmic program, its degree of objectivity and neutrality directly affects the decision outcome of the algorithm. An important feature of machine learning is that they require a large amount of input data to ‘learn’. If the input data itself is biased, then the results produced are biased as well. Particularly in machine learning algorithms, the absence of data samples from marginalised groups will infinitely circulate and reinforce society’s structural biases. Lerman (2013) argues that, due to poverty or geographic location, people living on the edge of big data are invariably left out in a non-random, systematic way, and their lives are less ‘datafied’ than the general population. Buolamwini and Gebru’s study “Gender shades” also illustrates this problem. Due to the lack of photos of many black women in data used to train facial recognition AI, the detection of black women is less accurate than for other groups of people. Some famous black women such as Oprah Winfrey and Michelle Obama are incorrectly identified as men by AI (Buolamwini and Gebru, 2018).
Understanding the current data collection practice for natural language processing AI is pertinent, because this research project is about collecting training data for a text-based AI. Due to the data-hungry nature of machine learning algorithms, a big amount of text-based data is mined from Reddit and used to train the latest natural language processing model GPT-3 (Piper, 2020). As Reddit is known for its misogynistic culture, it is not hard to imagine the algorithm trained by data from Reddit will also become misogynistic. Hence, a feminist intervention on AI training dataset is necessary.
Data feminism & Intersectional feminism
The concept of “intersectionality” was first coined by scholar Crenshaw (1989) to refer to multiple identities, which include gender, race, class, ethnicity, nationality, sexual orientation, religion, age, etc, and she proposes that “the experience of intersectionality is far from a superposition of racism and sexism”. D’Ignazio and Klein (2020) link “intersectionality” to “feminism” and argue that when discussing intersectional feminism, gender should not be used as a single framework for analysis, but needs to be examined alongside issues of race, migration status, history, social class, and especially about the individual female experience. As the intersectional approach suggests that people’s social identities can overlap, resulting in complex experiences of discrimination, intersectional feminism focuses on the voices of those who experience overlapping and simultaneous forms of oppression, in order to understand the depth of inequalities in any particular context (Dastagir, 2017).
The concept of intersectionality has been popular as a critical concept among academics since its emergence as an important dimension of race/class/gender studies, and has even been referred to as the ‘academic kernel of difference studies’ (Dill, 2009). Furthermore, the idea of intersectional feminism inspires some researchers, such as Sinders, D’Ignazio and Klein, to critique the status quo in the development of data and algorithms by examining the unequal power in data and how it leads to algorithmic bias. D’Ignazio and Klein (2020) present a new way of thinking about data science and data ethics, “data feminism”. Building on the notion of “data as power”, they point out that data collection and analysis is biased against anyone who does not fit the upper-class white male mould, and provide suggestions on how to deconstruct this power. Furthermore, as the data is envisioned and produced in a society significantly influenced by a history of white supremacy and patriarchy (Garbee, 2020), no matter how data is collected, it still remains confined within that system and still cannot be seen as truly equal.
Thoughtful data collection in practice
Methodology
Informed by an overview of existing scholarly work on algorithmic bias and the intersectional feminist approach to data, we attempt at building a dataset from scratch following the guidelines in Caroline Sinder’s research and art project “Feminist Data Set,” in which she notes that the data collection process is designed to be slow and thoughtful, countering the opaque and extractive nature of data collection in the current machine learning practices. We seek to critically analyze Feminist Data Set by going through the process of data collection ourselves. Although we will create a dataset as a result of the project, the main goal is not to produce a usable training dataset, but to be able to reflect on the process and to deepen our understanding on data collection, algorithmic bias and intersectional feminist interventions.
As Sinders notes in her documentation, there are two main criteria for building the dataset: 1) Data collected has to be feminist and intersectional; 2) For the purpose of building a chatbot, data should be in the format of written word, and part of the data has to be in colloquial language. In order to operate the project on a feasible scale, we focus on the topic of childcare as the theme of data collection.
Search engine bias
We start our data collection on Google fully aware of the search engine’s bias. Although this project’s focus is not a critique on Google’s algorithmic search per se, Google search engine is part of the problem that Feminist Data Set sets out to solve, i.e. algorithmic bias. Therefore, our data collection starts with critiquing the search engine we employed, and designing our query to confront the flaws in the tool we use in order to find intersectional feminist results effectively and efficiently.
Researchers, scholars and journalists have written about the search engine’s in-built bias, specifically towards women and people of color (Pariser, 2011; Noble, 2018; Tenner, 2018). According to Hindman (2008, p.43), “sites are ranked in a popularity contest in which each link is a vote, but the votes of popular sites carry more weight” in the ranking of Google search results. Through black feminism critique, Noble (2018) points out that Google “[biases] information toward the interests of the neoliberal capital and social elites in the United States.” Sinders (2020) also warns in her documentation that written text from marginalized groups can be hard to find. It is with this awareness that we collect data on the topic of childcare.
Query Design and data collection
We situate our data collection topic, childcare, in the context of intersectional feminism, which we have explored in literature review. It informs us to expand our query keywords from the stereotypes of “mother” and “female” to “unpaid work”, “migrant labor”, “race”, and policies welcomed by intersectional feminists such as “universal childcare”.
After searching with different keywords and browsing, we realize that it is not efficient to take the entire web as the source for query, as intersectional feminist contents are not the mainstream on the internet, and some of the results we’re looking for are not privileged by the search engine algorithm. Inspired by the ideas behind digital methods such as cross-spherical analysis (Rogers, 2013) and source distance (Rogers, 2019), we decide to use [site:] queries to look for childcare-related data purposefully within the intersectional feminist part of the internet. Out of those query results, we go beyond the first few pages of the results, and select ones that are truly intersectional and feminist. A list of the collected data can be seen here.
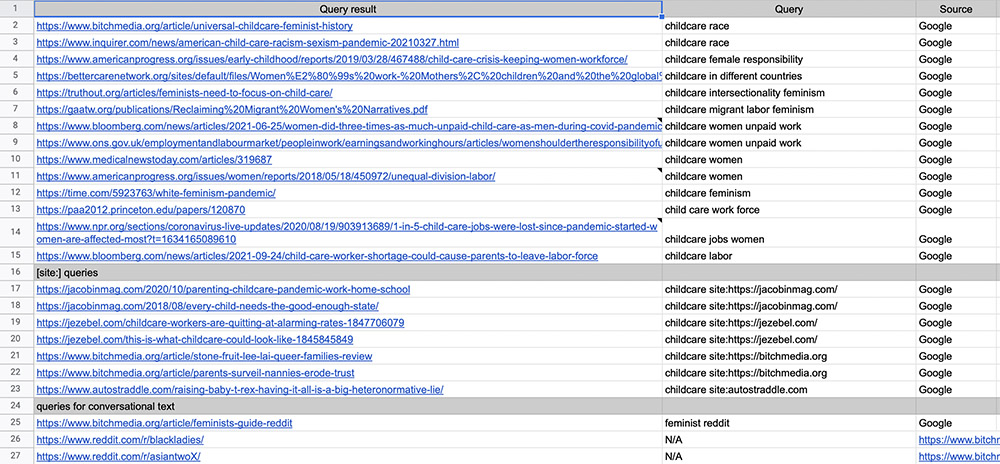
The same search approach applies when we look for conversational text for the purpose of training a chatbot AI. We first identify online forums where discussions on feminism may happen, and then check if the text is intersectional. We take into account the space where these conversations take place, and only collect data from spaces that are deemed fully public and open, such as Reddit and other online forums. We did not search on semi-open social platforms such as Facebook. We believe that taking extra care assessing what data to and not to collect is part of the practice that Feminist Data Set advocates for.
Discussion
Feminist Data Set’s contribution
Perhaps the most valuable contribution of Feminist Data Set is that it reclaimed data collection as a practice of resistance. The development of AI has been shaped by U.S. military and intelligence agencies since its early days, dating back to the 1950s; and data are collected to support the priority of military and state control (Crawford, 2021). Even though now AI technology has been largely commercialized, it doesn’t change the extractive nature of data collection––now serving the purpose of capitalist profit generation. Within the realm of academic research on AI, data collection is done under the guidance of specific ethical codes. Sinders’ Feminist Data Set is intentionally designed to start a public dialogue by subverting those power dynamics in data collection. In her toolkit documentation, she wrote, “What is a data set about a community that is made by that community? It can be a self-portrait, it can be protest, it can be a demand to be seen, it can be intervention or confrontation, or all of the above” (Sinders, 2020, p.7).
Feminist Data Set is a radical intervention in that it recognizes problems in existing datasets and seeks to solve the problem by creating new and better datasets. There are other types of intervention examining discriminations in algorithms, but most of them stop at identifying discrimination within existing algorithmic systems without offering solutions. In their research, Sandvig et al. (2014) borrowed the concept of audit study from social science and designed an analogous approach, algorithm audit, “to investigate normatively significant instances of discrimination involving computer algorithms operated by Internet platforms” (p.8). In the five audit study designs proposed, they mostly focused on identifying algorithmic discriminations from platforms, users and their interactions (Sandvig et al., 2014). Other interventions attempt at understanding how algorithms work without necessarily looking into the “black-box,” such as through what Bishop (2019) coined as “algorithm gossip” and what Bucher (2017) called “algorithmic imagination,” both examine how people perceive algorithms at work, to make the invisible visible.
Feminist Data Set’s limitation
There are some limitations with data collection as intervention to algorithmic bias. The most obvious one is that addressing the problems in datasets is only the first step of such intervention, as bias exists in each step of the process of designing an AI, which is outlined in the literature review. This section will discuss other less obvious limitations of data collection.
Data collection has its own paradox. When Taylor (2017) proposes the framework of data justice, she points out that data visibility can result in both access to representation and concerns over informational privacy. She emphasizes the importance of reconciling these seemingly contradicting perspectives by situating them in specific social and political conditions, without offering a one-fit-for-all answer (Taylor, 2017).
Informed by the data justice framework, careful assessment on the nature of data collected and the collection methods is necessary when applying Feminist Data Set in practice. Our project shedding light on the intersectional feminist perspective on childcare aims at collecting public available articles on the topic, hence can be evaluated as more of an effort to improve the visibility and representation of the topic from the perspective of the marginalized. However, we acknowledge that on some other issues, collecting sensitive and private data amounts to surveillance or violation of privacy. Raji et al. (2020) point out that efforts to collect images from a particular population to improve facial processing technology raise ethical concerns over consents and exploitation, even though the intention was to improve the technology to prevent it from discriminating against the population.
Moreover, on the practical level, we have to confront the mismatch between the intentionally slow process of data collection guided by Feminist Data Set and the huge amount of data necessary for machine learning purposes. Although we’re clear that the purpose of this project is not to create a usable dataset, the experience of creating a dataset from scratch helps us realize the demanding workload if this method were to be implemented in reality. A successful model that comes to mind is the Wikipedia Edit-a-thon organized by Art + Feminism, dedicated to adding information about women and people of color on the community-run online encyclopedia website Wikipedia. Moving forward, Feminist Data Set can explore the possibility of mobilizing a network of people to collectively build intersectional feminist datasets, so that the goal of having a dataset to train a machine learning algorithm can become achievable.
Conclusion
This research project situates Sinder’s Feminist Data Set in the academic debates on algorithmic bias and data feminism, and seek to critique it through the practice of building a dataset from scratch. The prevalent bias against women and marginalized groups in algorithms makes intersectional feminist interventions all the more necessary for data collection.
During the data collection process, we first examine the bias present in search engines, and design our queries accordingly. Based on the practice, we found that there are both limitations and contributions with data collection as an intervention to algorithmic bias: One of the shortcomings is that depending on the type of data collected, data collection can improve the representation of marginalized groups while raising ethical concerns. Another shortcoming of the data collection approach is its feasibility. We recognize Sinders’ project as a practice of resistance, questioning the current power imbalance of data collection mostly serving the interests of the state and for-profit companies. Feminist Data Set represents a force to reclaim data collection for the interest of the public, especially the marginalized group, a creative intervention on algorithmic bias, and a willingness to work towards its elimination.
Reference
Baeza-Yates, R., 2016. Data and algorithmic bias in the web. In Proceedings of the 8th ACM Conference on Web Science (pp. 1-1).
Bishop, S., 2019. Managing visibility on YouTube through algorithmic gossip. New Media & Society 21, 2589–2606. https://doi.org/10.1177/1461444819854731
Brogan, J., 2016. What’s the Deal With Algorithms? Slate. Available at https://slate.com/technology/2016/02/whats-the-deal-with-algorithms.html (Accessed 27 October 2021).
Bucher, T., 2017. The algorithmic imaginary: exploring the ordinary affects of Facebook algorithms. Information, Communication & Society 20, 30–44. https://doi.org/10.1080/1369118X.2016.1154086
Buolamwini, J., & Gebru, T. 2018. Gender shades: Intersectional accuracy disparities in commercial gender classification. In Conference on fairness, accountability and transparency (pp. 77-91). PMLR.
Cahn, N., Carbone, J., & Levit, N. 2019. Discrimination by Design. Ariz. St. LJ, 51, 1.
Collins, Patricia Hill, and Sirma Bilge. Intersectionality. Malden: Polity, 2016.
Crawford, K., 2021. Atlas of AI: power, politics, and the planetary costs of artificial intelligence. Yale University Press, New Haven.
Crenshaw, K. 1989. Demarginalizing the intersection of race and sex: A black feminist critique of antidiscrimination doctrine, feminist theory and antiracist politics. u. Chi. Legal f., 139.
Danks, D. and London, A.J., 2017, August. Algorithmic Bias in Autonomous Systems. In IJCAI (Vol. 17, pp. 4691-4697).
Dastagir, A., 2017. Bodies: Alia E. Dastagir, “What is Intersectional Feminism? A Look at a Term You May be Hearing A Lot”. [online] Bodies: A Digital Companion. Available at: https://scalar.usc.edu/works/bodies/alia-e-dastagir-what-is-intersectional-feminism-a-look-at-a-term-you-may-be-hearing-a-lot (Accessed 21 October 2021).
D’ignazio, C., & Klein, L. F. (2020). Data feminism. MIT press.
Dill, B. T. 2009. 10. Intersections, Identities, and Inequalities in Higher Education. In Emerging intersections (pp. 229-252). Rutgers University Press.
Friedman, B. and Nissenbaum, H., 1996. Bias in computer systems. ACM Transactions on Information Systems (TOIS), 14(3), pp.330-347.
Garbee, E., 2020. Review of DATA FEMINISM by Catherine D’Ignazio and Lauren F. Klein. [online] Issues in Science and Technology. Available at: https://issues.org/doing-the-work-data-feminism-review/ (Accessed 21 October 2021).
Lerman J. 2013. Big Data and Its Exclusions.Social Science Electronic Publishing,66:P.3,P.5.
Noble, S.U., 2018. Algorithms of oppression: how search engines reinforce racism. New York University Press, New York.
Pariser, E., 2011. The filter bubble: how the new personalized web is changing what we read and how we think. Penguin Books, New York.
Pasquinelli, M., & Joler, V. 2020. The Nooscope manifested: AI as instrument of knowledge extractivism. Ai & Society, 1-18.
Piper, K., 2020. GPT-3, explained: This new language AI is uncanny, funny — and a big deal. Vox. Available at https://www.vox.com/future-perfect/21355768/gpt-3-ai-openai-turing-test-language (Accessed 19 October 2021).
Raji, I.D., Gebru, T., Mitchell, M., Buolamwini, J., Lee, J., Denton, E., 2020. Saving Face: Investigating the Ethical Concerns of Facial Recognition Auditing, in: Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society, AIES ’20. Association for Computing Machinery, New York, NY, USA, pp. 145–151. https://doi.org/10.1145/3375627.3375820
Sandvig, C., Hamilton, K., Karahalios, K. and Langbort, C., 2014. Auditing algorithms: Research methods for detecting discrimination on internet platforms. Data and discrimination: converting critical concerns into productive inquiry, 22, pp.4349-4357.
Sheng, E., Chang, K.-W., Natarajan, P., Peng, N., 2019. The Woman Worked as a Babysitter: On Biases in Language Generation. arXiv:1909.01326 [cs].
Sinders, C., 2020. Feminist Data Set. Available at https://carolinesinders.com/wp-content/uploads/2020/05/Feminist-Data-Set-Final-Draft-2020-0526.pdf (Accessed 19 October 2021).
Taylor, L., 2017. What is data justice? The case for connecting digital rights and freedoms globally. Big Data & Society 4, 2053951717736335. https://doi.org/10.1177/2053951717736335
Tenner, E., 2018. How to Get Better, Less Biased Search Results. Time. Available at https://time.com/5318918/search-results-engine-google-bias-trusted-sources/ (Accessed 24 October 2021).